3.8 Ensemble learning
Contents
3.8 Ensemble learning#
Ensemble learning involves combining several weak learners to build a strong learner that is more robust and generalizable. A popular example is the choice of the Random Forest algorithm that is a lot stronger than individual Decision Trees that compose the Forest.
Several key advantages to ensemble learning are:
Reduced Overfitting: Ensemble methods, particularly bagging techniques like Random Forests, mitigate the risk of overfitting by combining predictions from multiple models.
Improved generalization: As a follow up from the previous point, ensemble methods may capture complex relationships more effectively and shows improved generalization on diverse data.
Robustness to noise and outliers: Ensemble methods, by aggregating predictions from multiple models, are less susceptible to the impact of individual noisy or outlier-laden data points. This results in more robust predictions, particularly in the presence of imperfect or uncertain data.
Increased model stability: Individual models might perform well on certain subsets of the data but poorly on others. By combining diverse models, ensembles provide a more stable and reliable prediction across various scenarios and subgroups within geospatial datasets.
Below we will
import numpy as np
from sklearn.datasets import load_digits
digits = load_digits()
# explore data type
data,y = digits["data"].copy(),digits["target"].copy()
print(type(data[0][:]),type(y[0]))
# note that we do not modify the raw data that is stored on the digits dictionary.
<class 'numpy.ndarray'> <class 'numpy.int64'>
from sklearn.preprocessing import MinMaxScaler
from sklearn.model_selection import train_test_split
scaler = MinMaxScaler()
scaler.fit_transform(data)# fit the model for data normalization
newdata = scaler.transform(data) # transform the data. watch that data was converted to a numpy array
# Split data into 50% train and 50% test subsets
print(f"There are {data.shape[0]} data samples")
X_train, X_test, y_train, y_test = train_test_split(
data, y, test_size=0.2, shuffle=False)
There are 1797 data samples
1. Voting Classifier#
Aggregate the predictions of each classifier and predict the class that gets the most votes.
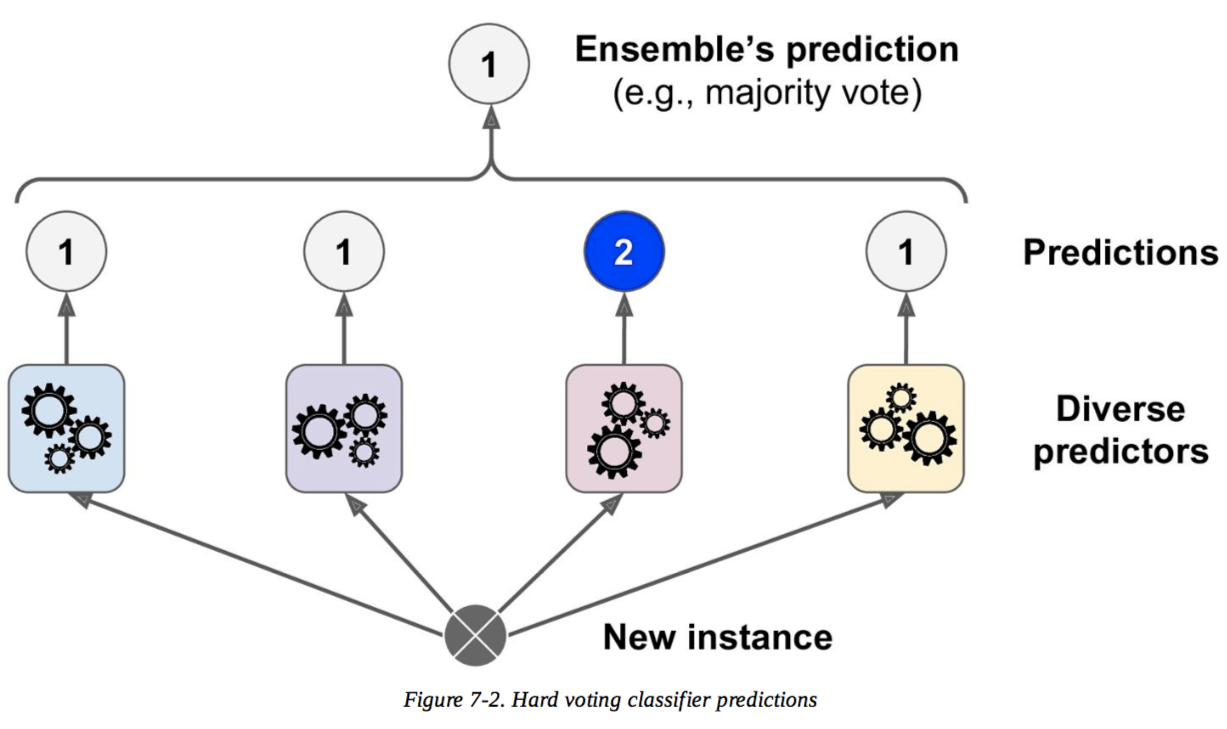 From “Hands on Machine Learning With Sci-kit Learn, Keras, and Tensorflow” (Gueron).
From “Hands on Machine Learning With Sci-kit Learn, Keras, and Tensorflow” (Gueron).
Next, we are going to create an ensemble of models. The models
from sklearn.ensemble import VotingClassifier
from sklearn.naive_bayes import GaussianNB
from sklearn.ensemble import RandomForestClassifier
from sklearn.svm import SVC
from sklearn.metrics import accuracy_score
from sklearn.model_selection import cross_val_score
svc_clf = SVC() # model design
nb_clf = GaussianNB()
rf_clf = RandomForestClassifier()
voting_clf = VotingClassifier(
estimators = [ ('nb',nb_clf) , ('rf',rf_clf),('svc',svc_clf)],
voting='hard')
voting_clf.fit(X_train, y_train) # learn
y_pred=voting_clf.predict(X_test)
accuracy_score(y_test,y_pred)
0.925
Compare with individual ones
for clf in (nb_clf,rf_clf,svc_clf,voting_clf):
scores = cross_val_score(clf, data, y, scoring='accuracy', cv=15)
print(clf.__class__.__name__,scores.mean())
GaussianNB 0.8263632119514472
RandomForestClassifier 0.9615219421101775
SVC 0.9793790849673202
VotingClassifier 0.9687815126050421
Note that taking the average of the predicted probability, instead of its max, is also a possibility. One can only evaluate the classifiers that output probabilities, which SVM does not do by default. Set the voting to soft to compare with the mean proba.
2. Bagging and Pasting#
This approaches uses the same model algorithm but resampling on the training set. For resampling with replacement (bootstrap), it is called bagging; for resampling without replacement, it is called pasting.
Several models are trained on different data, then the predictions are aggregated (statistical mode for classification and average for regression). The aggregated model tends to have a lower variance and bias, similar to what it would get if it were trained on the entire data.
In the example below, you can implement BaggingClassifier in sklearn and explore by changing the number of model or bootstrapping value
from sklearn.ensemble import BaggingClassifier
from sklearn.neighbors import KNeighborsClassifier
bag_clf = BaggingClassifier(
base_estimator = KNeighborsClassifier(),n_estimators=100, # n_estimator is the number of models to train
max_samples=1000,bootstrap=True, # bootstrap is for bagging vs pasting
n_jobs=-1,#number of CPU cores independently used for training and prediction. Use -1 for all available score
)
scores=cross_val_score(bag_clf,data,y,cv=5)
print('mean accuracy',scores.mean())
/Users/marinedenolle/opt/miniconda3/envs/mlgeo/lib/python3.9/site-packages/sklearn/ensemble/_base.py:156: FutureWarning: `base_estimator` was renamed to `estimator` in version 1.2 and will be removed in 1.4.
warnings.warn(
/Users/marinedenolle/opt/miniconda3/envs/mlgeo/lib/python3.9/site-packages/sklearn/ensemble/_base.py:156: FutureWarning: `base_estimator` was renamed to `estimator` in version 1.2 and will be removed in 1.4.
warnings.warn(
/Users/marinedenolle/opt/miniconda3/envs/mlgeo/lib/python3.9/site-packages/sklearn/ensemble/_base.py:156: FutureWarning: `base_estimator` was renamed to `estimator` in version 1.2 and will be removed in 1.4.
warnings.warn(
/Users/marinedenolle/opt/miniconda3/envs/mlgeo/lib/python3.9/site-packages/sklearn/ensemble/_base.py:156: FutureWarning: `base_estimator` was renamed to `estimator` in version 1.2 and will be removed in 1.4.
warnings.warn(
/Users/marinedenolle/opt/miniconda3/envs/mlgeo/lib/python3.9/site-packages/sklearn/ensemble/_base.py:156: FutureWarning: `base_estimator` was renamed to `estimator` in version 1.2 and will be removed in 1.4.
warnings.warn(
mean accuracy 0.9599473847106159
One property of the resampling replacement is that for \(m\) sampled data with replacement, up to 63% of the data tends to be sampled in average, as \(m\) tends to the size of the total number of samples. This means that in average, 37% of the data never gets sampled. That portion act as a testing set. To get the accuracy score on that portion of the data, we can set the argument for BaggingClassifer oob_score=True and compare the with the score from the test set.
from sklearn.model_selection import cross_val_predict
bag_clf = BaggingClassifier(
base_estimator = KNeighborsClassifier(),n_estimators=100, # n_estimator is the number of models to train
max_samples=100,bootstrap=True, # bootstrap is for bagging vs pasting
n_jobs=-1,oob_score=True,#number of CPU cores independently used for training and prediction. Use -1 for all available score
)
scores=cross_val_predict(bag_clf,X_test,y_test,cv=5) # the size of max_samples
/Users/marinedenolle/opt/miniconda3/envs/mlgeo/lib/python3.9/site-packages/sklearn/ensemble/_base.py:156: FutureWarning: `base_estimator` was renamed to `estimator` in version 1.2 and will be removed in 1.4.
warnings.warn(
/Users/marinedenolle/opt/miniconda3/envs/mlgeo/lib/python3.9/site-packages/sklearn/ensemble/_base.py:156: FutureWarning: `base_estimator` was renamed to `estimator` in version 1.2 and will be removed in 1.4.
warnings.warn(
/Users/marinedenolle/opt/miniconda3/envs/mlgeo/lib/python3.9/site-packages/sklearn/ensemble/_base.py:156: FutureWarning: `base_estimator` was renamed to `estimator` in version 1.2 and will be removed in 1.4.
warnings.warn(
/Users/marinedenolle/opt/miniconda3/envs/mlgeo/lib/python3.9/site-packages/sklearn/ensemble/_base.py:156: FutureWarning: `base_estimator` was renamed to `estimator` in version 1.2 and will be removed in 1.4.
warnings.warn(
/Users/marinedenolle/opt/miniconda3/envs/mlgeo/lib/python3.9/site-packages/sklearn/ensemble/_base.py:156: FutureWarning: `base_estimator` was renamed to `estimator` in version 1.2 and will be removed in 1.4.
warnings.warn(
3. Boosting#
The idea behind boosting methods is to train predictors sequentially, each trying to correct its predecessor.
3.1 AdaBoost#
The AdaBoost algorithm trains a new predictor by paying more attention (up-weighting) the bad predictions from the previous predictor. For instance, in a classification, a first predictor will be underfitting the data and misclassifying labels. The second predictor weights more strongly the data that was misclassified. The learning_rate parameters set the magnitude of that weighting.
AdaBoost work on any classifier that outputs probabilities (e.g., DecisionTrees, KNN; look for the classifiers that can take the function predict_proba()).
from sklearn.ensemble import AdaBoostClassifier
from sklearn.tree import DecisionTreeClassifier
ada_clf = AdaBoostClassifier(
DecisionTreeClassifier(max_depth=100),n_estimators=2000,
algorithm='SAMME.R',learning_rate=0.01) # use the algorithm SAMME for binary classificaiton, SAMME.R for multi-class
ada_clf.fit(X_train,y_train)
y_pred=ada_clf.predict(X_test)
print(accuracy_score(y_pred,y_test))
0.8055555555555556
3.2 Gradient Boosting#
Algorithm that sequentially fits the data and its predicted residuals:
Single small estimator is trained on the data (a weak learner)
Second small estimator is trained on the residuals between the data and the predicted data from the first estimator (a second weak learner). The residuals are getting smaller
A third small estimator…
The final prediction is the sum of all predictions.
Gradient boosting is typically used using Decision Trees. n_estimators limits the total number of trees. When n_estimators is very large, the model will overfit the data. To regularize the training, one can find the optimal number of estimators by looking at the progressive reduction of the residuals until the residual curve flattens.
The learning_rate is a hyperparameter that scales the contribution of each tree. When learn_rate is low, the GB will need more trees to git.
The most popular algorithm is XGBoost for
!pip install xgboost
Collecting xgboost
Downloading xgboost-2.0.2-py3-none-macosx_12_0_arm64.whl (1.9 MB)
|████████████████████████████████| 1.9 MB 1.2 MB/s eta 0:00:01
?25hRequirement already satisfied: scipy in /Users/marinedenolle/opt/miniconda3/envs/mlgeo/lib/python3.9/site-packages (from xgboost) (1.11.3)
Requirement already satisfied: numpy in /Users/marinedenolle/opt/miniconda3/envs/mlgeo/lib/python3.9/site-packages (from xgboost) (1.26.0)
Installing collected packages: xgboost
Successfully installed xgboost-2.0.2
import xgboost as xgb
Nclass = len(np.unique(y_train))
train = xgb.DMatrix(X_train,label=y_train)
test = xgb.DMatrix(X_test,label=y_test)
print(Nclass)
10
param = {
'max_depth':40, # depth of the trees
'eta':0.3, # learning rate
'objective':'multi:softmax',
'num_class':Nclass
}
epoch = 10
model=xgb.train(param,train,epoch)
pred = model.predict(test)
accuracy_score(pred,y_test)
0.8861111111111111
4. Stacking#
Each estimator may predict a value. Instead of taking the majority vote, one can aggregate the probabilities using another estimator. The last estimator is called a meta learning that takes all of the predictions and fit to the labeled prediction.