3.4 Multiclass Classification
Contents
3.4 Multiclass Classification#
Here we will use several well known classifiers: Support Vector Machine, k-nearest neighbors, and Random Forest.
We will practice with the MNIST data set. It is a data set of images of handwritten numbers.
import numpy as np
from sklearn.datasets import load_digits,fetch_openml
from sklearn.metrics import ConfusionMatrixDisplay
digits = load_digits()
digits.keys()
dict_keys(['data', 'target', 'frame', 'feature_names', 'target_names', 'images', 'DESCR'])
The data is vector of floats. The target is an integer that is the attribute of the data. How are the data balanced between the classes? How many samples are there per class?
# explore data type
data,y = digits["data"].copy(),digits["target"].copy()
print(type(data[0][:]),type(y[0]))
# note that we do not modify the raw data that is stored on the digits dictionary.
<class 'numpy.ndarray'> <class 'numpy.int64'>
how many classes are there? Since the classes are integers, we can count the number of classes using the function “unique”
Nclasses = len(np.unique(y))
print(np.unique(y))
print(Nclasses)
[0 1 2 3 4 5 6 7 8 9]
10
3.1 Data preparation#
First print and plot the data.
# plot the data
import matplotlib.pyplot as plt
# plot the first 4 data and their labels.
_, axes = plt.subplots(nrows=1, ncols=4, figsize=(10, 3))
for ax, image, label in zip(axes, digits.images, digits.target):
ax.set_axis_off()
ax.imshow(image, cmap=plt.cm.gray_r, interpolation='nearest')
ax.set_title('Training: %i' % label)

3.2 Data re-scaling#
We could use MinMaxScaler from sklearn.preprocessing but since the formula for that is (x-min)/(max-min) and our min is 0, we could directly calculate x/max.
The raw data is still stored in the dictionary digits and so we can modify the data variable in place.
additional tutorials here
print(min(data[0]),max(data[0]))
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
scaler.fit_transform(data)# fit the model for data normalization
newdata = scaler.transform(data) # transform the data. watch that data was converted to a numpy array
print(type(newdata))
print(newdata)
0.0 15.0
<class 'numpy.ndarray'>
[[0. 0. 0.3125 ... 0. 0. 0. ]
[0. 0. 0. ... 0.625 0. 0. ]
[0. 0. 0. ... 1. 0.5625 0. ]
...
[0. 0. 0.0625 ... 0.375 0. 0. ]
[0. 0. 0.125 ... 0.75 0. 0. ]
[0. 0. 0.625 ... 0.75 0.0625 0. ]]
3.3 Train-test split#
# Split data into 50% train and 50% test subsets
from sklearn.model_selection import train_test_split
print(f"There are {data.shape[0]} data samples")
X_train, X_test, y_train, y_test = train_test_split(
data, y, test_size=0.5, shuffle=False)
There are 1797 data samples
import sklearn
from sklearn import metrics
from sklearn.svm import SVC
from sklearn.neighbors import KNeighborsClassifier
from sklearn.ensemble import RandomForestClassifier
# Support Vector Machine classifier
clf = SVC(gamma=0.001) # model design
clf.fit(X_train, y_train) # learn
svc_prediction = clf.predict(X_test) # predict on test
print("SVC Accuracy:", metrics.accuracy_score(y_true=y_test ,y_pred=svc_prediction))
# K-nearest Neighbors
knn_clf = KNeighborsClassifier() # model design
knn_clf.fit(X_train, y_train) # learn
knn_prediction = knn_clf.predict(X_test) # predict on test
print("K-nearest Neighbors Accuracy:", metrics.accuracy_score(y_true=y_test ,y_pred=knn_prediction))
# Random Forest
rf_clf = RandomForestClassifier(random_state=42, verbose=True) # model design
rf_clf.fit(X_train, y_train)# learn
rf_prediction = rf_clf.predict(X_test) # predict on test
print("Random Forest Accuracy:", metrics.accuracy_score(y_true=y_test ,y_pred=rf_prediction))
SVC Accuracy: 0.9688542825361512
K-nearest Neighbors Accuracy: 0.9555061179087876
Random Forest Accuracy: 0.92880978865406
[Parallel(n_jobs=1)]: Done 49 tasks | elapsed: 0.1s
[Parallel(n_jobs=1)]: Done 49 tasks | elapsed: 0.0s
_, axes = plt.subplots(nrows=1, ncols=4, figsize=(10, 3))
for ax, image, prediction in zip(axes, X_test, rf_prediction):
ax.set_axis_off()
image = image.reshape(8, 8)
ax.imshow(image, cmap=plt.cm.gray_r, interpolation='nearest')
ax.set_title(f'Prediction: {prediction}')

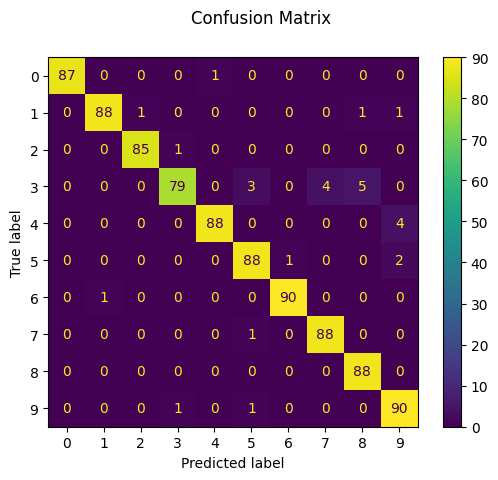
print("Support Vector Machine")
print(f"Classification report for classifier {clf}:\n"
f"{metrics.classification_report(y_test, svc_prediction)}\n")
disp = ConfusionMatrixDisplay.from_estimator(clf, X_test, y_test)
disp.figure_.suptitle("Confusion Matrix")
# print(f"Confusion matrix:\n{disp.confusion_matrix}")
plt.show()
Support Vector Machine
Classification report for classifier SVC(gamma=0.001):
precision recall f1-score support
0 1.00 0.99 0.99 88
1 0.99 0.97 0.98 91
2 0.99 0.99 0.99 86
3 0.98 0.87 0.92 91
4 0.99 0.96 0.97 92
5 0.95 0.97 0.96 91
6 0.99 0.99 0.99 91
7 0.96 0.99 0.97 89
8 0.94 1.00 0.97 88
9 0.93 0.98 0.95 92
accuracy 0.97 899
macro avg 0.97 0.97 0.97 899
weighted avg 0.97 0.97 0.97 899
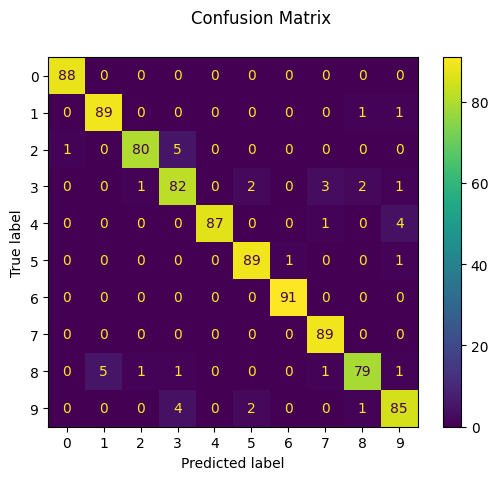
print("K-nearest neighbors")
print(f"Classification report for classifier {knn_clf}:\n"
f"{metrics.classification_report(y_test, knn_prediction)}\n")
disp = ConfusionMatrixDisplay.from_estimator(knn_clf, X_test, y_test)
disp.figure_.suptitle("Confusion Matrix")
# print(f"Confusion matrix:\n{disp.confusion_matrix}")
plt.show()
K-nearest neighbors
Classification report for classifier KNeighborsClassifier():
precision recall f1-score support
0 0.99 1.00 0.99 88
1 0.95 0.98 0.96 91
2 0.98 0.93 0.95 86
3 0.89 0.90 0.90 91
4 1.00 0.95 0.97 92
5 0.96 0.98 0.97 91
6 0.99 1.00 0.99 91
7 0.95 1.00 0.97 89
8 0.95 0.90 0.92 88
9 0.91 0.92 0.92 92
accuracy 0.96 899
macro avg 0.96 0.96 0.96 899
weighted avg 0.96 0.96 0.96 899
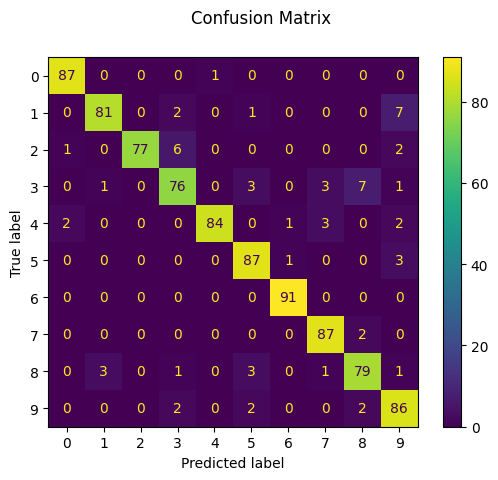
print("Random Forest")
print(f"Classification report for classifier {rf_clf}:\n"
f"{metrics.classification_report(y_test, rf_prediction)}\n")
disp = ConfusionMatrixDisplay.from_estimator(rf_clf, X_test, y_test)
disp.figure_.suptitle("Confusion Matrix")
# print(f"Confusion matrix:\n{disp.confusion_matrix}")
plt.show()
Random Forest
Classification report for classifier RandomForestClassifier(random_state=42, verbose=True):
precision recall f1-score support
0 0.97 0.99 0.98 88
1 0.95 0.89 0.92 91
2 1.00 0.90 0.94 86
3 0.87 0.84 0.85 91
4 0.99 0.91 0.95 92
5 0.91 0.96 0.93 91
6 0.98 1.00 0.99 91
7 0.93 0.98 0.95 89
8 0.88 0.90 0.89 88
9 0.84 0.93 0.89 92
accuracy 0.93 899
macro avg 0.93 0.93 0.93 899
weighted avg 0.93 0.93 0.93 899
[Parallel(n_jobs=1)]: Done 49 tasks | elapsed: 0.0s
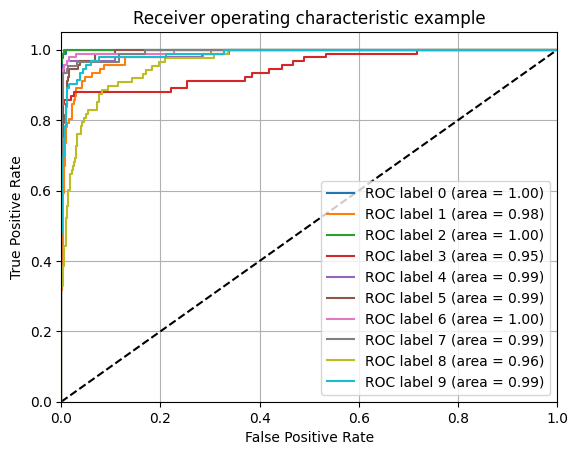
from sklearn.metrics import roc_curve,roc_auc_score, precision_recall_curve, RocCurveDisplay, PrecisionRecallDisplay
from sklearn.multiclass import OneVsRestClassifier
from sklearn.preprocessing import label_binarize
from sklearn import svm
from sklearn.metrics import roc_curve, auc
random_state = np.random.RandomState(0)
classifier = OneVsRestClassifier(svm.SVC(kernel='linear', probability=True,
random_state=random_state))
y = label_binarize(y, classes=[0,1,2,3,4,5,6,7,8,9])
X_train, X_test, y_train, y_test = train_test_split(
data, y, test_size=0.5, shuffle=False)
y_score = classifier.fit(X_train, y_train).decision_function(X_test)
# Compute ROC curve and ROC area for each class
fpr = dict()
tpr = dict()
roc_auc = dict()
for i in range(Nclasses):
fpr[i], tpr[i], _ = roc_curve(y_test[:,i], y_score[:, i])
roc_auc[i] = auc(fpr[i], tpr[i])
# Plot of a ROC curve for a specific class
plt.figure()
plt.plot([0, 1], [0, 1], 'k--')
for i in range(Nclasses):
plt.plot(fpr[i], tpr[i], label='ROC label %1.0f (area = %0.2f)' % (i,roc_auc[i]))
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.grid(True)
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('Receiver operating characteristic example')
plt.legend(loc="lower right")
<matplotlib.legend.Legend at 0x7fd65cb311b0>
from sklearn.model_selection import cross_val_predict
y_train_pred = cross_val_predict(clf, X_train, y_train, cv=3) # predict using K-fold cross validation
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
/workspaces/mlgeo-instructor/book/Chapter3-MachineLearning/3.4_multiclass_classification.ipynb Cell 20 line 2
<a href='vscode-notebook-cell://codespaces%2Bcurly-winner-7647wqr96rhr49q/workspaces/mlgeo-instructor/book/Chapter3-MachineLearning/3.4_multiclass_classification.ipynb#X25sdnNjb2RlLXJlbW90ZQ%3D%3D?line=0'>1</a> from sklearn.model_selection import cross_val_predict
----> <a href='vscode-notebook-cell://codespaces%2Bcurly-winner-7647wqr96rhr49q/workspaces/mlgeo-instructor/book/Chapter3-MachineLearning/3.4_multiclass_classification.ipynb#X25sdnNjb2RlLXJlbW90ZQ%3D%3D?line=1'>2</a> y_train_pred = cross_val_predict(clf,X_train,y_train,cv=3) # predict using K-fold cross validation
File ~/.local/lib/python3.10/site-packages/sklearn/model_selection/_validation.py:1033, in cross_val_predict(estimator, X, y, groups, cv, n_jobs, verbose, fit_params, pre_dispatch, method)
1030 # We clone the estimator to make sure that all the folds are
1031 # independent, and that it is pickle-able.
1032 parallel = Parallel(n_jobs=n_jobs, verbose=verbose, pre_dispatch=pre_dispatch)
-> 1033 predictions = parallel(
1034 delayed(_fit_and_predict)(
1035 clone(estimator), X, y, train, test, verbose, fit_params, method
1036 )
1037 for train, test in splits
1038 )
1040 inv_test_indices = np.empty(len(test_indices), dtype=int)
1041 inv_test_indices[test_indices] = np.arange(len(test_indices))
File ~/.local/lib/python3.10/site-packages/sklearn/utils/parallel.py:65, in Parallel.__call__(self, iterable)
60 config = get_config()
61 iterable_with_config = (
62 (_with_config(delayed_func, config), args, kwargs)
63 for delayed_func, args, kwargs in iterable
64 )
---> 65 return super().__call__(iterable_with_config)
File ~/.local/lib/python3.10/site-packages/joblib/parallel.py:1863, in Parallel.__call__(self, iterable)
1861 output = self._get_sequential_output(iterable)
1862 next(output)
-> 1863 return output if self.return_generator else list(output)
1865 # Let's create an ID that uniquely identifies the current call. If the
1866 # call is interrupted early and that the same instance is immediately
1867 # re-used, this id will be used to prevent workers that were
1868 # concurrently finalizing a task from the previous call to run the
1869 # callback.
1870 with self._lock:
File ~/.local/lib/python3.10/site-packages/joblib/parallel.py:1792, in Parallel._get_sequential_output(self, iterable)
1790 self.n_dispatched_batches += 1
1791 self.n_dispatched_tasks += 1
-> 1792 res = func(*args, **kwargs)
1793 self.n_completed_tasks += 1
1794 self.print_progress()
File ~/.local/lib/python3.10/site-packages/sklearn/utils/parallel.py:127, in _FuncWrapper.__call__(self, *args, **kwargs)
125 config = {}
126 with config_context(**config):
--> 127 return self.function(*args, **kwargs)
File ~/.local/lib/python3.10/site-packages/sklearn/model_selection/_validation.py:1115, in _fit_and_predict(estimator, X, y, train, test, verbose, fit_params, method)
1113 estimator.fit(X_train, **fit_params)
1114 else:
-> 1115 estimator.fit(X_train, y_train, **fit_params)
1116 func = getattr(estimator, method)
1117 predictions = func(X_test)
File ~/.local/lib/python3.10/site-packages/sklearn/base.py:1152, in _fit_context.<locals>.decorator.<locals>.wrapper(estimator, *args, **kwargs)
1145 estimator._validate_params()
1147 with config_context(
1148 skip_parameter_validation=(
1149 prefer_skip_nested_validation or global_skip_validation
1150 )
1151 ):
-> 1152 return fit_method(estimator, *args, **kwargs)
File ~/.local/lib/python3.10/site-packages/sklearn/svm/_base.py:190, in BaseLibSVM.fit(self, X, y, sample_weight)
188 check_consistent_length(X, y)
189 else:
--> 190 X, y = self._validate_data(
191 X,
192 y,
193 dtype=np.float64,
194 order="C",
195 accept_sparse="csr",
196 accept_large_sparse=False,
197 )
199 y = self._validate_targets(y)
201 sample_weight = np.asarray(
202 [] if sample_weight is None else sample_weight, dtype=np.float64
203 )
File ~/.local/lib/python3.10/site-packages/sklearn/base.py:622, in BaseEstimator._validate_data(self, X, y, reset, validate_separately, cast_to_ndarray, **check_params)
620 y = check_array(y, input_name="y", **check_y_params)
621 else:
--> 622 X, y = check_X_y(X, y, **check_params)
623 out = X, y
625 if not no_val_X and check_params.get("ensure_2d", True):
File ~/.local/lib/python3.10/site-packages/sklearn/utils/validation.py:1162, in check_X_y(X, y, accept_sparse, accept_large_sparse, dtype, order, copy, force_all_finite, ensure_2d, allow_nd, multi_output, ensure_min_samples, ensure_min_features, y_numeric, estimator)
1142 raise ValueError(
1143 f"{estimator_name} requires y to be passed, but the target y is None"
1144 )
1146 X = check_array(
1147 X,
1148 accept_sparse=accept_sparse,
(...)
1159 input_name="X",
1160 )
-> 1162 y = _check_y(y, multi_output=multi_output, y_numeric=y_numeric, estimator=estimator)
1164 check_consistent_length(X, y)
1166 return X, y
File ~/.local/lib/python3.10/site-packages/sklearn/utils/validation.py:1183, in _check_y(y, multi_output, y_numeric, estimator)
1181 else:
1182 estimator_name = _check_estimator_name(estimator)
-> 1183 y = column_or_1d(y, warn=True)
1184 _assert_all_finite(y, input_name="y", estimator_name=estimator_name)
1185 _ensure_no_complex_data(y)
File ~/.local/lib/python3.10/site-packages/sklearn/utils/validation.py:1244, in column_or_1d(y, dtype, warn)
1233 warnings.warn(
1234 (
1235 "A column-vector y was passed when a 1d array was"
(...)
1240 stacklevel=2,
1241 )
1242 return _asarray_with_order(xp.reshape(y, (-1,)), order="C", xp=xp)
-> 1244 raise ValueError(
1245 "y should be a 1d array, got an array of shape {} instead.".format(shape)
1246 )
ValueError: y should be a 1d array, got an array of shape (598, 10) instead.