4.0 The Perceptron
Contents
4.0 The Perceptron#
The perceptron is the basis for neural networks.
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
Let’s create a perceptron#
class simplePerceptron:
# Activation functions
def __none(x):
return x
def __sigmoid(x): # define activation function
return 1/(1+np.exp(-x))
def __step(x):
out = np.zeros(x.shape)
out[x >= 0] = 1
return out
possibleActivations = {
'none': __none,
'sigmoid': __sigmoid,
'step': __step
}
# Initialize
def __init__(self, w=None, b_w=None, activation=None):
if w is None:
self.w = 0
else:
self.w = w
if b_w is None:
self.b_w = 0
else:
self.b_w = b_w
if (activation is None) or (activation not in self.possibleActivations):
self.activation = 'none'
else:
self.activation = activation
def setWs(self, w, b_w):
self.w = w
self.b_w = b_w
def predict(self, x):
# x *should* be a mxn np array, where each row corresponds to an observation
# Sum everything
weightedSum = np.zeros(x.shape[0])
for i in range(len(self.w)):
weightedSum = self.w[i] * x[:, i]
summed = weightedSum + (1 * self.b_w)
return self.possibleActivations[self.activation](summed)
Let us test out this perceptron#
ourPerceptron = simplePerceptron(w=[0], b_w=1, activation='none')
ourPerceptron.setWs([1], 0)
ourPerceptron.activation
testInput = np.array([[100, -1, 0.1]]).T
ourPerceptron.predict(testInput)
array([100. , -1. , 0.1])
Remember the Iris dataset?#
from sklearn import datasets
iris = datasets.load_iris()
# Let's take a look at the dataset
fig, ax = plt.subplots()
scatter = ax.scatter(iris.data[:, 0], iris.data[:, 1], c=iris.target)
ax.set(xlabel=iris.feature_names[0], ylabel=iris.feature_names[1])
ax.legend(scatter.legend_elements()[0], iris.target_names, loc="lower right", title="Classes");
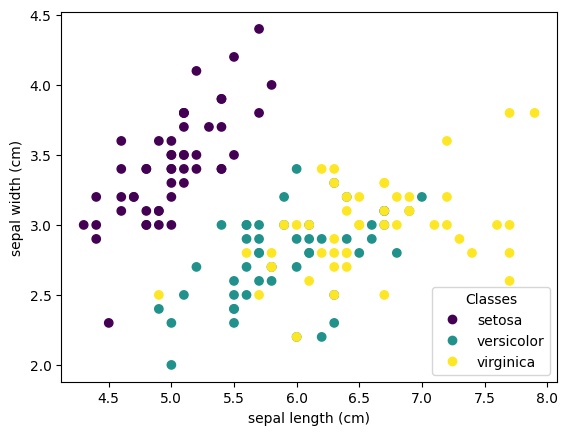
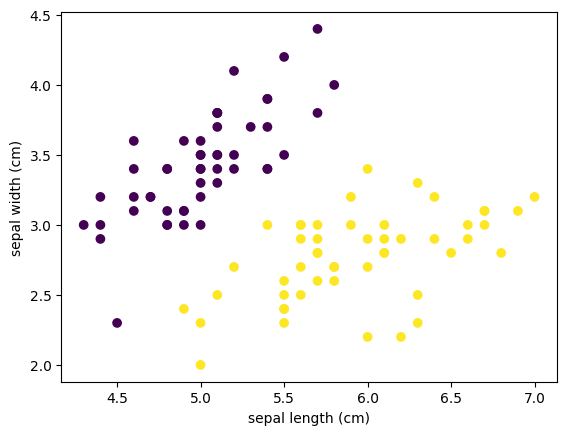
For the purposes of producing a linearly separable dataset, we’re going to drop the virginica class from the dataset and only loot epal width and length.
simpleInputs = iris.data[iris.target!=2,0:2]
simpleOutputs = iris.target[iris.target!=2]
# Shuffle these two arrays
# Random generator
rng = np.random.default_rng()
p = rng.permutation(len(simpleInputs))
simpleInputs = simpleInputs[p, :]
simpleOutputs = simpleOutputs[p]
fig, ax = plt.subplots()
ax.scatter(simpleInputs[:, 0], simpleInputs[:,1], c=simpleOutputs)
ax.set(xlabel=iris.feature_names[0], ylabel=iris.feature_names[1])
[Text(0.5, 0, 'sepal length (cm)'), Text(0, 0.5, 'sepal width (cm)')]
The perceptron rule#
To train our perceptron, we will start with our weights set to 0.
percept = simplePerceptron(w=np.array([0, 0]).T, b_w=0, activation='step')
testArray = np.array([[1,2], [2,3], [3,4]])
percept.predict(simpleInputs)
array([1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.,
1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.,
1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.,
1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.,
1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.,
1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.])
Now, for some number of iterations, we’re going to:
Make a prediction for one item in our dataset with our perceptron
Update our weights using the following rule:
\(w_j = w_j + \Delta w_j\)
where
\(\Delta w_j=\eta(t^i−o^i)x^i_j\)
where \(w_j\) is the weight, \(\eta\) is our learning rate, \(t^i\) and \(o^i\) refer to the target and output, respectively, and \(x^i_j\) is the corresponding input.
In the case of a 2D dataset, we are updating 3 weights: 2 for the inputs and 1 for the bias (for the latter, there is no input to consider).
Keep going until we’re happy with the solution. In our case, we will set a stopping point of 25 iterations.
iterations = 100
learningRate = .0001
whichItem = 0
# Now, for each iteration:
for i in range(iterations):
# Make a prediction for some item
thisInput = np.reshape(simpleInputs[whichItem, :], (1, -1))
thisTarget = simpleOutputs[whichItem]
out = percept.predict(thisInput)
# Now, let's figure out the "error"
error = thisTarget - out
newWeights = np.zeros(percept.w.size)
# Let's update our weights
for j in range(len(percept.w)):
update = (learningRate * error * thisInput[:, j])
newWeights[j] = percept.w[j] + update
percept.setWs(newWeights, percept.b_w + (learningRate * error))
# Next item
whichItem = whichItem + 1
percept.w
/tmp/ipykernel_2931/2113147933.py:17: DeprecationWarning: Conversion of an array with ndim > 0 to a scalar is deprecated, and will error in future. Ensure you extract a single element from your array before performing this operation. (Deprecated NumPy 1.25.)
newWeights[j] = percept.w[j] + update
array([ 4.95e-03, -6.00e-05])
percept.predict(simpleInputs)
array([1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.,
1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.,
1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.,
1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.,
1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.,
1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.])
!pip install mlxtend
from mlxtend.plotting import plot_decision_regions
plot_decision_regions(simpleInputs, simpleOutputs, clf=percept)
plt.title('Perceptron')
plt.xlabel('sepal length [cm]')
plt.ylabel('petal length [cm]')
plt.show()
Collecting mlxtend
Downloading mlxtend-0.23.4-py3-none-any.whl (1.4 MB)
?25l ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 0.0/1.4 MB ? eta -:--:--
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 1.4/1.4 MB 64.2 MB/s eta 0:00:00
?25h
Requirement already satisfied: scipy>=1.2.1 in /usr/share/miniconda3/envs/geosmart/lib/python3.10/site-packages (from mlxtend) (1.11.4)
Requirement already satisfied: numpy>=1.16.2 in /usr/share/miniconda3/envs/geosmart/lib/python3.10/site-packages (from mlxtend) (1.26.4)
Requirement already satisfied: matplotlib>=3.0.0 in /usr/share/miniconda3/envs/geosmart/lib/python3.10/site-packages (from mlxtend) (3.7.5)
Requirement already satisfied: pandas>=0.24.2 in /usr/share/miniconda3/envs/geosmart/lib/python3.10/site-packages (from mlxtend) (2.1.4)
Requirement already satisfied: scikit-learn>=1.3.1 in /usr/share/miniconda3/envs/geosmart/lib/python3.10/site-packages (from mlxtend) (1.4.2)
Requirement already satisfied: joblib>=0.13.2 in /usr/share/miniconda3/envs/geosmart/lib/python3.10/site-packages (from mlxtend) (1.3.2)
Requirement already satisfied: contourpy>=1.0.1 in /usr/share/miniconda3/envs/geosmart/lib/python3.10/site-packages (from matplotlib>=3.0.0->mlxtend) (1.3.1)
Requirement already satisfied: fonttools>=4.22.0 in /usr/share/miniconda3/envs/geosmart/lib/python3.10/site-packages (from matplotlib>=3.0.0->mlxtend) (4.55.7)
Requirement already satisfied: python-dateutil>=2.7 in /usr/share/miniconda3/envs/geosmart/lib/python3.10/site-packages (from matplotlib>=3.0.0->mlxtend) (2.8.2)
Requirement already satisfied: pillow>=6.2.0 in /usr/share/miniconda3/envs/geosmart/lib/python3.10/site-packages (from matplotlib>=3.0.0->mlxtend) (11.1.0)
Requirement already satisfied: kiwisolver>=1.0.1 in /usr/share/miniconda3/envs/geosmart/lib/python3.10/site-packages (from matplotlib>=3.0.0->mlxtend) (1.4.8)
Requirement already satisfied: pyparsing>=2.3.1 in /usr/share/miniconda3/envs/geosmart/lib/python3.10/site-packages (from matplotlib>=3.0.0->mlxtend) (3.0.9)
Requirement already satisfied: cycler>=0.10 in /usr/share/miniconda3/envs/geosmart/lib/python3.10/site-packages (from matplotlib>=3.0.0->mlxtend) (0.12.1)
Requirement already satisfied: packaging>=20.0 in /usr/share/miniconda3/envs/geosmart/lib/python3.10/site-packages (from matplotlib>=3.0.0->mlxtend) (21.3)
Requirement already satisfied: tzdata>=2022.1 in /usr/share/miniconda3/envs/geosmart/lib/python3.10/site-packages (from pandas>=0.24.2->mlxtend) (2025.1)
Requirement already satisfied: pytz>=2020.1 in /usr/share/miniconda3/envs/geosmart/lib/python3.10/site-packages (from pandas>=0.24.2->mlxtend) (2022.1)
Requirement already satisfied: threadpoolctl>=2.0.0 in /usr/share/miniconda3/envs/geosmart/lib/python3.10/site-packages (from scikit-learn>=1.3.1->mlxtend) (3.5.0)
Requirement already satisfied: six>=1.5 in /usr/share/miniconda3/envs/geosmart/lib/python3.10/site-packages (from python-dateutil>=2.7->matplotlib>=3.0.0->mlxtend) (1.16.0)
Installing collected packages: mlxtend
Successfully installed mlxtend-0.23.4
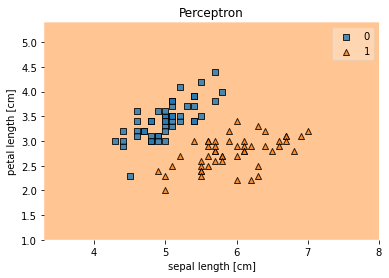
Awesome! We just implemented an online algorithm.
What about fitting a line to some data with our little perceptron?#
# We create a linear dataset with some noise
# How many data?
num = 100
xRange = [0, 5]
yRange = [0, 2.5]
x = np.linspace(xRange[0], xRange[1], num=num)
y = np.linspace(yRange[0], yRange[1], num=num)
noise_factor = 0.5
def noise(k):
# Add some noise
return k+((rng.random()*2)-1)*noise_factor
x = np.vectorize(noise)(x)
y = np.vectorize(noise)(y)
# Shuffle x and y
p = rng.permutation(num)
x = x[p]
y = y[p]
fig, ax = plt.subplots()
ax.scatter(x, y, color='k')
ax.set_aspect('equal')
ax.set_axisbelow(True)
ax.grid(color='gray', linestyle='dashed')
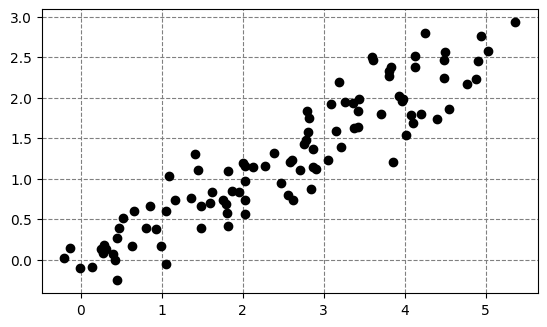
We need to train our perceptron
We should define a cost function (here, mean square error)
def mseCost(prediction, target):
mse = (np.square(prediction - target)).mean()
return mse
What is the cost of a perfect return?
mseCost(y,y)
0.0
The other thing we would like to do is a define a learning algorithm (here, gradient descent)
def gradientDescent(perceptron, costFunction, trainInput, trainTarget, learningRate, numIterations, stoppingCriterion):
weights = []
biases = []
costs = []
numInputs = len(trainInput)
previousCost = None
for i in range(numIterations):
# Run your prediction
prediction = perceptron.predict(trainInput)
# Determine your cost
thisCost = costFunction(prediction, trainTarget)
# Is the change in cost less than (or equal to) the stoppingCriterion?
if previousCost and np.absolute(previousCost - thisCost) <= stoppingCriterion:
break
# If not, update previousCost
previousCost = thisCost
# Add this weight, this bias, and this cost to weights, biases, and costs, respectively
weights.append(perceptron.w)
biases.append(perceptron.b_w)
costs.append(thisCost)
# Great, let's now calculate the errors first
er = np.subtract(trainTarget, prediction)
# What does the weight update look like?
weightUpdate = learningRate * np.dot(trainInput.T, er)
# Do the same for the bias weight update
biasWeightUpdate = learningRate * np.sum(er)
# Now, update the weights and bias weight
perceptron.setWs(perceptron.w + weightUpdate, perceptron.b_w + biasWeightUpdate)
return {'weights': weights, 'biases': biases, 'costs': costs}
numIterations = 10000
# Initialize a weight and bias
ourPerceptron.setWs([0],0)
# Run our gradient descent
output = gradientDescent(ourPerceptron, mseCost, np.reshape(x[0:50], (-1, 1)), y[0:50], 0.001, numIterations, 1e-6)
# A function to plot outputs from gradient descent
def plotOutputs(gdOutput):
# How many iterations were actually run?
iterationsRan = len(gdOutput['costs'])
toPlot = ['weights', 'biases', 'costs']
pltCount = 3
fig, axes = plt.subplots(1, pltCount, figsize=(12, 4))
for i in range(pltCount):
axes[i].plot(range(iterationsRan), gdOutput[toPlot[i]], color='r')
axes[i].set_xlabel('Iteration #')
axes[i].set_ylabel('Value')
axes[i].set_title(toPlot[i].capitalize())
axes[i].set_axisbelow(True)
axes[i].xaxis.grid(color='gray', linestyle='dashed')
fig.tight_layout()
return fig
plotOutputs(output);
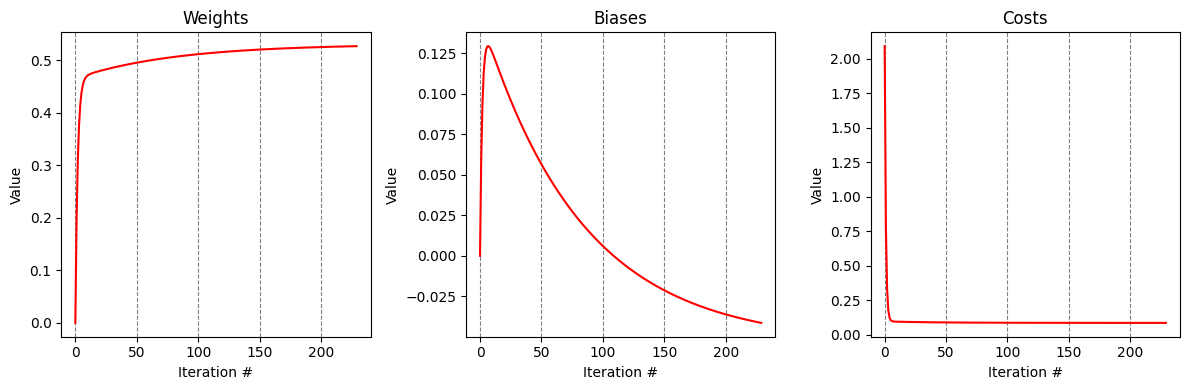
# Let's try out our little perceptron on data it hasn't seen before
testPredictions = ourPerceptron.predict(np.reshape(x[50:100], (-1,1)))
testCost = mseCost(testPredictions, np.reshape(y[50:100], (-1,1)))
'The mean square error of our little perceptron is: %f' % testCost
'The mean square error of our little perceptron is: 1.073622'
def compareOutputs(x, y, perceptron, xRange):
fig, ax = plt.subplots(figsize=(12,4))
ax.scatter(x, y, color='k')
ax.set_aspect('equal')
forLine = np.linspace(xRange[0], xRange[1])
ax.plot(forLine, perceptron.predict(np.reshape(forLine, (-1,1))), color='r', linestyle='dotted', linewidth=1)
# How well do we do relative to OLS?
OLSoutput = LinearRegression().fit(x[0:50].reshape(-1,1),y[0:50])
ax.plot(forLine, OLSoutput.predict(forLine.reshape(-1,1)), color='b', linestyle='dashed', linewidth=1)
ax.set_axisbelow(True)
ax.grid(color='gray', linestyle='dashed')
ax.legend(['Data', 'Perceptron fit', 'OLS fit'])
return fig;
compareOutputs(x, y, ourPerceptron, xRange);
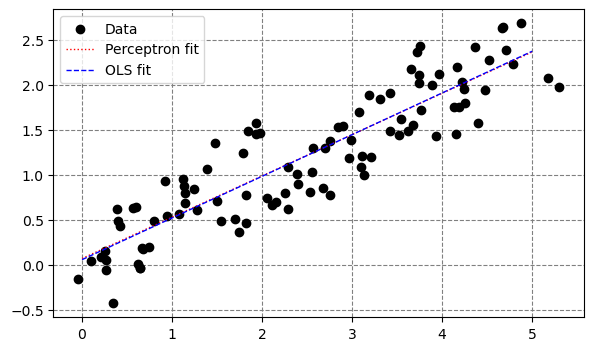
Now, let’s explore how our learning choices impact our model
!pip install ipywidgets
import ipywidgets as widgets
from IPython.display import display, clear_output
%matplotlib inline
Requirement already satisfied: ipywidgets in /usr/share/miniconda3/envs/geosmart/lib/python3.10/site-packages (7.7.0)
Requirement already satisfied: ipython-genutils~=0.2.0 in /usr/share/miniconda3/envs/geosmart/lib/python3.10/site-packages (from ipywidgets) (0.2.0)
Requirement already satisfied: ipython>=4.0.0 in /usr/share/miniconda3/envs/geosmart/lib/python3.10/site-packages (from ipywidgets) (8.4.0)
Requirement already satisfied: jupyterlab-widgets>=1.0.0 in /usr/share/miniconda3/envs/geosmart/lib/python3.10/site-packages (from ipywidgets) (1.1.0)
Requirement already satisfied: traitlets>=4.3.1 in /usr/share/miniconda3/envs/geosmart/lib/python3.10/site-packages (from ipywidgets) (5.2.2.post1)
Requirement already satisfied: ipykernel>=4.5.1 in /usr/share/miniconda3/envs/geosmart/lib/python3.10/site-packages (from ipywidgets) (6.13.1)
Requirement already satisfied: widgetsnbextension~=3.6.0 in /usr/share/miniconda3/envs/geosmart/lib/python3.10/site-packages (from ipywidgets) (3.6.0)
Requirement already satisfied: nbformat>=4.2.0 in /usr/share/miniconda3/envs/geosmart/lib/python3.10/site-packages (from ipywidgets) (5.4.0)
Requirement already satisfied: packaging in /usr/share/miniconda3/envs/geosmart/lib/python3.10/site-packages (from ipykernel>=4.5.1->ipywidgets) (21.3)
Requirement already satisfied: nest-asyncio in /usr/share/miniconda3/envs/geosmart/lib/python3.10/site-packages (from ipykernel>=4.5.1->ipywidgets) (1.5.5)
Requirement already satisfied: debugpy>=1.0 in /usr/share/miniconda3/envs/geosmart/lib/python3.10/site-packages (from ipykernel>=4.5.1->ipywidgets) (1.6.0)
Requirement already satisfied: psutil in /usr/share/miniconda3/envs/geosmart/lib/python3.10/site-packages (from ipykernel>=4.5.1->ipywidgets) (5.9.1)
Requirement already satisfied: matplotlib-inline>=0.1 in /usr/share/miniconda3/envs/geosmart/lib/python3.10/site-packages (from ipykernel>=4.5.1->ipywidgets) (0.1.3)
Requirement already satisfied: jupyter-client>=6.1.12 in /usr/share/miniconda3/envs/geosmart/lib/python3.10/site-packages (from ipykernel>=4.5.1->ipywidgets) (7.3.4)
Requirement already satisfied: tornado>=6.1 in /usr/share/miniconda3/envs/geosmart/lib/python3.10/site-packages (from ipykernel>=4.5.1->ipywidgets) (6.1)
Requirement already satisfied: setuptools>=18.5 in /usr/share/miniconda3/envs/geosmart/lib/python3.10/site-packages (from ipython>=4.0.0->ipywidgets) (65.5.1)
Requirement already satisfied: pexpect>4.3 in /usr/share/miniconda3/envs/geosmart/lib/python3.10/site-packages (from ipython>=4.0.0->ipywidgets) (4.8.0)
Requirement already satisfied: prompt-toolkit!=3.0.0,!=3.0.1,<3.1.0,>=2.0.0 in /usr/share/miniconda3/envs/geosmart/lib/python3.10/site-packages (from ipython>=4.0.0->ipywidgets) (3.0.29)
Requirement already satisfied: jedi>=0.16 in /usr/share/miniconda3/envs/geosmart/lib/python3.10/site-packages (from ipython>=4.0.0->ipywidgets) (0.18.1)
Requirement already satisfied: backcall in /usr/share/miniconda3/envs/geosmart/lib/python3.10/site-packages (from ipython>=4.0.0->ipywidgets) (0.2.0)
Requirement already satisfied: decorator in /usr/share/miniconda3/envs/geosmart/lib/python3.10/site-packages (from ipython>=4.0.0->ipywidgets) (5.1.1)
Requirement already satisfied: pygments>=2.4.0 in /usr/share/miniconda3/envs/geosmart/lib/python3.10/site-packages (from ipython>=4.0.0->ipywidgets) (2.12.0)
Requirement already satisfied: stack-data in /usr/share/miniconda3/envs/geosmart/lib/python3.10/site-packages (from ipython>=4.0.0->ipywidgets) (0.2.0)
Requirement already satisfied: pickleshare in /usr/share/miniconda3/envs/geosmart/lib/python3.10/site-packages (from ipython>=4.0.0->ipywidgets) (0.7.5)
Requirement already satisfied: jsonschema>=2.6 in /usr/share/miniconda3/envs/geosmart/lib/python3.10/site-packages (from nbformat>=4.2.0->ipywidgets) (3.2.0)
Requirement already satisfied: jupyter-core in /usr/share/miniconda3/envs/geosmart/lib/python3.10/site-packages (from nbformat>=4.2.0->ipywidgets) (4.10.0)
Requirement already satisfied: fastjsonschema in /usr/share/miniconda3/envs/geosmart/lib/python3.10/site-packages (from nbformat>=4.2.0->ipywidgets) (2.15.3)
Requirement already satisfied: notebook>=4.4.1 in /usr/share/miniconda3/envs/geosmart/lib/python3.10/site-packages (from widgetsnbextension~=3.6.0->ipywidgets) (6.4.12)
Requirement already satisfied: parso<0.9.0,>=0.8.0 in /usr/share/miniconda3/envs/geosmart/lib/python3.10/site-packages (from jedi>=0.16->ipython>=4.0.0->ipywidgets) (0.8.3)
Requirement already satisfied: six>=1.11.0 in /usr/share/miniconda3/envs/geosmart/lib/python3.10/site-packages (from jsonschema>=2.6->nbformat>=4.2.0->ipywidgets) (1.16.0)
Requirement already satisfied: pyrsistent>=0.14.0 in /usr/share/miniconda3/envs/geosmart/lib/python3.10/site-packages (from jsonschema>=2.6->nbformat>=4.2.0->ipywidgets) (0.18.1)
Requirement already satisfied: attrs>=17.4.0 in /usr/share/miniconda3/envs/geosmart/lib/python3.10/site-packages (from jsonschema>=2.6->nbformat>=4.2.0->ipywidgets) (21.4.0)
Requirement already satisfied: entrypoints in /usr/share/miniconda3/envs/geosmart/lib/python3.10/site-packages (from jupyter-client>=6.1.12->ipykernel>=4.5.1->ipywidgets) (0.4)
Requirement already satisfied: python-dateutil>=2.8.2 in /usr/share/miniconda3/envs/geosmart/lib/python3.10/site-packages (from jupyter-client>=6.1.12->ipykernel>=4.5.1->ipywidgets) (2.8.2)
Requirement already satisfied: pyzmq>=23.0 in /usr/share/miniconda3/envs/geosmart/lib/python3.10/site-packages (from jupyter-client>=6.1.12->ipykernel>=4.5.1->ipywidgets) (23.1.0)
Requirement already satisfied: nbconvert>=5 in /usr/share/miniconda3/envs/geosmart/lib/python3.10/site-packages (from notebook>=4.4.1->widgetsnbextension~=3.6.0->ipywidgets) (6.5.0)
Requirement already satisfied: argon2-cffi in /usr/share/miniconda3/envs/geosmart/lib/python3.10/site-packages (from notebook>=4.4.1->widgetsnbextension~=3.6.0->ipywidgets) (21.3.0)
Requirement already satisfied: jinja2 in /usr/share/miniconda3/envs/geosmart/lib/python3.10/site-packages (from notebook>=4.4.1->widgetsnbextension~=3.6.0->ipywidgets) (3.1.2)
Requirement already satisfied: prometheus-client in /usr/share/miniconda3/envs/geosmart/lib/python3.10/site-packages (from notebook>=4.4.1->widgetsnbextension~=3.6.0->ipywidgets) (0.14.1)
Requirement already satisfied: terminado>=0.8.3 in /usr/share/miniconda3/envs/geosmart/lib/python3.10/site-packages (from notebook>=4.4.1->widgetsnbextension~=3.6.0->ipywidgets) (0.15.0)
Requirement already satisfied: Send2Trash>=1.8.0 in /usr/share/miniconda3/envs/geosmart/lib/python3.10/site-packages (from notebook>=4.4.1->widgetsnbextension~=3.6.0->ipywidgets) (1.8.0)
Requirement already satisfied: ptyprocess>=0.5 in /usr/share/miniconda3/envs/geosmart/lib/python3.10/site-packages (from pexpect>4.3->ipython>=4.0.0->ipywidgets) (0.7.0)
Requirement already satisfied: wcwidth in /usr/share/miniconda3/envs/geosmart/lib/python3.10/site-packages (from prompt-toolkit!=3.0.0,!=3.0.1,<3.1.0,>=2.0.0->ipython>=4.0.0->ipywidgets) (0.2.5)
Requirement already satisfied: pyparsing!=3.0.5,>=2.0.2 in /usr/share/miniconda3/envs/geosmart/lib/python3.10/site-packages (from packaging->ipykernel>=4.5.1->ipywidgets) (3.0.9)
Requirement already satisfied: executing in /usr/share/miniconda3/envs/geosmart/lib/python3.10/site-packages (from stack-data->ipython>=4.0.0->ipywidgets) (0.8.3)
Requirement already satisfied: asttokens in /usr/share/miniconda3/envs/geosmart/lib/python3.10/site-packages (from stack-data->ipython>=4.0.0->ipywidgets) (2.0.5)
Requirement already satisfied: pure-eval in /usr/share/miniconda3/envs/geosmart/lib/python3.10/site-packages (from stack-data->ipython>=4.0.0->ipywidgets) (0.2.2)
Requirement already satisfied: mistune<2,>=0.8.1 in /usr/share/miniconda3/envs/geosmart/lib/python3.10/site-packages (from nbconvert>=5->notebook>=4.4.1->widgetsnbextension~=3.6.0->ipywidgets) (0.8.4)
Requirement already satisfied: MarkupSafe>=2.0 in /usr/share/miniconda3/envs/geosmart/lib/python3.10/site-packages (from nbconvert>=5->notebook>=4.4.1->widgetsnbextension~=3.6.0->ipywidgets) (2.1.1)
Requirement already satisfied: jupyterlab-pygments in /usr/share/miniconda3/envs/geosmart/lib/python3.10/site-packages (from nbconvert>=5->notebook>=4.4.1->widgetsnbextension~=3.6.0->ipywidgets) (0.2.2)
Requirement already satisfied: bleach in /usr/share/miniconda3/envs/geosmart/lib/python3.10/site-packages (from nbconvert>=5->notebook>=4.4.1->widgetsnbextension~=3.6.0->ipywidgets) (5.0.0)
Requirement already satisfied: nbclient>=0.5.0 in /usr/share/miniconda3/envs/geosmart/lib/python3.10/site-packages (from nbconvert>=5->notebook>=4.4.1->widgetsnbextension~=3.6.0->ipywidgets) (0.5.13)
Requirement already satisfied: pandocfilters>=1.4.1 in /usr/share/miniconda3/envs/geosmart/lib/python3.10/site-packages (from nbconvert>=5->notebook>=4.4.1->widgetsnbextension~=3.6.0->ipywidgets) (1.5.0)
Requirement already satisfied: beautifulsoup4 in /usr/share/miniconda3/envs/geosmart/lib/python3.10/site-packages (from nbconvert>=5->notebook>=4.4.1->widgetsnbextension~=3.6.0->ipywidgets) (4.11.1)
Requirement already satisfied: tinycss2 in /usr/share/miniconda3/envs/geosmart/lib/python3.10/site-packages (from nbconvert>=5->notebook>=4.4.1->widgetsnbextension~=3.6.0->ipywidgets) (1.1.1)
Requirement already satisfied: defusedxml in /usr/share/miniconda3/envs/geosmart/lib/python3.10/site-packages (from nbconvert>=5->notebook>=4.4.1->widgetsnbextension~=3.6.0->ipywidgets) (0.7.1)
Requirement already satisfied: argon2-cffi-bindings in /usr/share/miniconda3/envs/geosmart/lib/python3.10/site-packages (from argon2-cffi->notebook>=4.4.1->widgetsnbextension~=3.6.0->ipywidgets) (21.2.0)
Requirement already satisfied: cffi>=1.0.1 in /usr/share/miniconda3/envs/geosmart/lib/python3.10/site-packages (from argon2-cffi-bindings->argon2-cffi->notebook>=4.4.1->widgetsnbextension~=3.6.0->ipywidgets) (1.15.0)
Requirement already satisfied: soupsieve>1.2 in /usr/share/miniconda3/envs/geosmart/lib/python3.10/site-packages (from beautifulsoup4->nbconvert>=5->notebook>=4.4.1->widgetsnbextension~=3.6.0->ipywidgets) (2.3.1)
Requirement already satisfied: webencodings in /usr/share/miniconda3/envs/geosmart/lib/python3.10/site-packages (from bleach->nbconvert>=5->notebook>=4.4.1->widgetsnbextension~=3.6.0->ipywidgets) (0.5.1)
Requirement already satisfied: pycparser in /usr/share/miniconda3/envs/geosmart/lib/python3.10/site-packages (from cffi>=1.0.1->argon2-cffi-bindings->argon2-cffi->notebook>=4.4.1->widgetsnbextension~=3.6.0->ipywidgets) (2.21)
# Create inputs
learningRateSlider = widgets.FloatLogSlider(
value=.001,
min=-6,
max=1.0,
step=1,
description='Learning Rate:'
)
iterationsSlider = widgets.Dropdown(
options=[1, 10, 100, 1000, 10000, 100000],
value=100,
description='Number of Iterations:'
)
stoppingCriterionSlider = widgets.FloatLogSlider(
value=1e-4,
min=-8,
max=1,
step=1,
description='Stopping Criterion:'
)
startingWeight = widgets.BoundedFloatText(
value=0,
min=-50,
max=50,
description='Weight'
)
startingBias = widgets.BoundedFloatText(
value=0,
min=-50,
max=5000,
description='Bias'
)
# Create the "Update" button
updateBtn = widgets.Button(description="Update")
outputWidget = widgets.Output()
# Define the function to run when the "Update" button is clicked
def updateClick(_):
with outputWidget:
clear_output(wait=True)
learningRate = learningRateSlider.value
numIterations = iterationsSlider.value
stoppingCriterion = stoppingCriterionSlider.value
ourPerceptron.setWs([startingWeight.value], startingBias.value)
output = gradientDescent(ourPerceptron, mseCost, np.reshape(x[0:50], (-1, 1)), y[0:50], learningRate, numIterations, stoppingCriterion)
display(compareOutputs(x, y, ourPerceptron, xRange))
display(plotOutputs(output))
# Set the function to be called when the button is clicked
updateBtn.on_click(updateClick)
# Display the widgets
display(learningRateSlider, iterationsSlider, stoppingCriterionSlider, startingWeight, startingBias, updateBtn, outputWidget)