4.7 Physics-Informed Neural Networks
Contents
4.7 Physics-Informed Neural Networks#
1. Introduction to Physics-Informed Neural Networks (PINNs)#
Physics-Informed Neural Networks (PINNs) incorporate physical laws, expressed as partial differential equations (PDEs) or other governing equations, directly into the training of neural networks. By embedding the physics into the loss function, PINNs enable data-driven solutions while adhering to fundamental principles like conservation laws. They can:
Solve PDEs with or without data.
Require fewer labeled datasets since they rely on physics.
Integrate prior knowledge into machine learning workflows.
Geosciences often rely on simulations governed by complex equations (e.g., Navier-Stokes, diffusion, or wave equations). PINNs provide a bridge between traditional computational modeling and machine learning, especially when data is scarce or noisy.
Temperature Diffusion in Earth’s Crust:
Application in modeling geothermal energy potential.
Reference: Study on thermal conductivity prediction using sparse borehole data and PINNs.
Seismic Wave Propagation:
Real-time simulation of earthquake waves through heterogeneous media.
Reference: PINNs for solving elastic wave equations in complex geological domains.
Groundwater Flow Dynamics:
Modeling aquifer responses to pumping and recharge events. PINNs have helped solve the Darcy equation and advection-diffusion equations in hydrogeology to simulate groundwater movement and pollutant dispersion.
Why PINNs in Geosciences?#
Many geoscientific processes are governed by well-known PDEs (e.g., Navier-Stokes equations, heat diffusion equations).
Combining sparse field data with known physical laws helps PINNs solve problems like seismic imaging, weather prediction, and subsurface modeling.
2. Mathematical Framework of PINNs#
Components of a PINN:
Neural Network (NN): Approximates the solution ( u(x,t) ) or similar dependent variables.
PDE: The governing equation ( \mathcal{L}(u, x, t) = 0 ), where ( \mathcal{L} ) is the differential operator.
Loss Function:
\(\text{Loss} = \text{Data Loss} + \text{Physics Loss},\)
where
Data Loss enforces agreement with observations.
Physics Loss ensures the NN respects the governing equations.
Optimization:
Solve for NN parameters \(\theta\) by minimizing the combined loss using gradient-based optimizers.
3. Python Example: Solving the Heat Equation with PyTorch#
We will solve the 1D Heat Equation:
\( \frac{\partial T}{\partial t} = \alpha \frac{\partial^2 T}{\partial x^2},\)
where \(T(x,t)\) is temperature, \(\alpha\) is the thermal diffusivity.
import functools
import matplotlib.pyplot as plt
import numpy as np
import torch
DEVICE = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
torch.manual_seed(42)
np.random.seed(10)
Create Synthetic Data#
A solution to this problem, given initial and boundary conditions at \(T(x=0,t=0)T_0\),
\( T(x,t) = T_0 \exp (-Rt) \)
First, we create synthetic, toy, noisy data.
def cooling_law(time, Tenv, T0, R):
T = Tenv + (T0 - Tenv) * np.exp(-R * time)
return T
Tenv = 25
T0 = 100
R = 0.005
times = np.linspace(0, 1000, 1000)
eq = functools.partial(cooling_law, Tenv=Tenv, T0=T0, R=R)
temps = eq(times)
# Make training data
t = np.linspace(0, 300, 10)
T = eq(t) + 2 * np.random.randn(10)
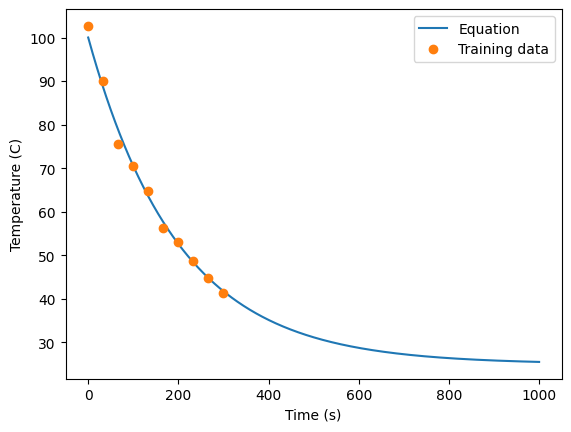
plt.plot(times, temps)
plt.plot(t, T, 'o')
plt.legend(['Equation', 'Training data'])
plt.ylabel('Temperature (C)')
plt.xlabel('Time (s)')
Text(0.5, 0, 'Time (s)')
import torch
import torch.nn as nn
import torch.optim as optim
import torch.utils.data as thdat
def np_to_th(x):
n_samples = len(x)
return torch.from_numpy(x).to(torch.float).to(DEVICE).reshape(n_samples, -1)
def grad(outputs, inputs):
"""Computes the partial derivative of
an output with respect to an input.
Args:
outputs: (N, 1) tensor
inputs: (N, D) tensor
"""
return torch.autograd.grad(
outputs, inputs, grad_outputs=torch.ones_like(outputs), create_graph=True
)
class Net(nn.Module):
def __init__(
self,
input_dim,
output_dim,
n_units=100,
epochs=1000,
loss=nn.MSELoss(),
lr=1e-3,
loss2=None,
loss2_weight=0.1,
) -> None:
super().__init__()
self.epochs = epochs
self.loss = loss
self.loss2 = loss2
self.loss2_weight = loss2_weight
self.lr = lr
self.n_units = n_units
self.layers = nn.Sequential(
nn.Linear(input_dim, self.n_units),
nn.ReLU(),
nn.Linear(self.n_units, self.n_units),
nn.ReLU(),
nn.Linear(self.n_units, self.n_units),
nn.ReLU(),
nn.Linear(self.n_units, self.n_units),
nn.ReLU(),
)
self.out = nn.Linear(self.n_units, output_dim)
def forward(self, x):
h = self.layers(x)
out = self.out(h)
return out
def fit(self, X, y):
Xt = np_to_th(X)
yt = np_to_th(y)
optimiser = optim.Adam(self.parameters(), lr=self.lr)
self.train()
losses = []
for ep in range(self.epochs):
optimiser.zero_grad()
outputs = self.forward(Xt)
loss = self.loss(yt, outputs)
if self.loss2:
loss += self.loss2_weight + self.loss2_weight * self.loss2(self)
loss.backward()
optimiser.step()
losses.append(loss.item())
if ep % int(self.epochs / 10) == 0:
print(f"Epoch {ep}/{self.epochs}, loss: {losses[-1]:.2f}")
return losses
def predict(self, X):
self.eval()
out = self.forward(np_to_th(X))
return out.detach().cpu().numpy()
class NetDiscovery(Net):
def __init__(
self,
input_dim,
output_dim,
n_units=100,
epochs=1000,
loss=nn.MSELoss(),
lr=0.001,
loss2=None,
loss2_weight=0.1,
) -> None:
super().__init__(
input_dim, output_dim, n_units, epochs, loss, lr, loss2, loss2_weight
)
self.r = nn.Parameter(data=torch.tensor([0.]))
net = Net(1,1, loss2=None, epochs=2000, lr=1e-4).to(DEVICE)
losses = net.fit(t, T)
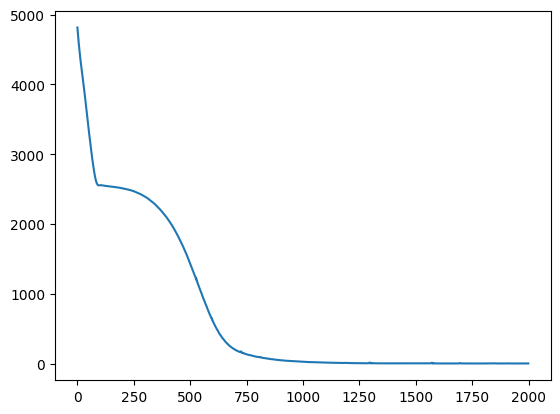
plt.plot(losses)
# plt.yscale('log')
Epoch 0/2000, loss: 4713.87
Epoch 200/2000, loss: 2527.58
Epoch 400/2000, loss: 2296.65
Epoch 600/2000, loss: 1254.55
Epoch 800/2000, loss: 77.51
Epoch 1000/2000, loss: 2.77
Epoch 1200/2000, loss: 2.24
Epoch 1400/2000, loss: 1.95
Epoch 1600/2000, loss: 1.80
Epoch 1800/2000, loss: 1.64
[<matplotlib.lines.Line2D at 0x168881070>]
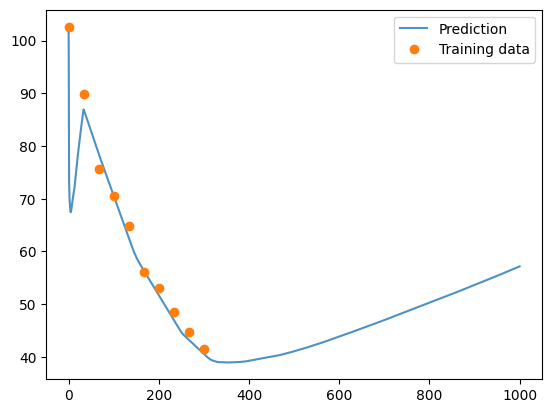
prediction_temp_baseline = net.predict(times)
plt.plot(times, prediction_temp_baseline, alpha=0.8)
plt.plot(t, T, 'o')
plt.legend(['Prediction', 'Training data'])
<matplotlib.legend.Legend at 0x1688d9dc0>
# define the second loss function
def l2_reg(model: torch.nn.Module):
return torch.sum(sum([p.pow(2.) for p in model.parameters()]))
netreg = Net(1,1, loss2=l2_reg, epochs=20000, lr=1e-4, loss2_weight=1).to(DEVICE)
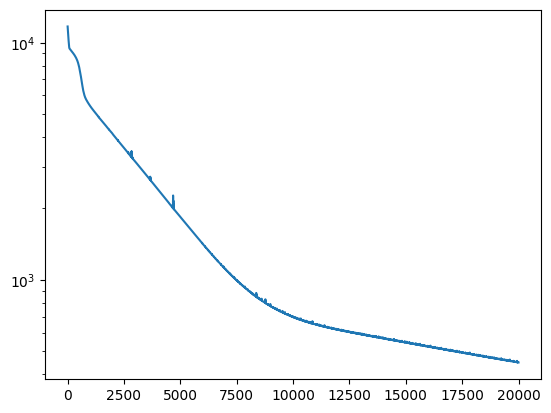
losses = netreg.fit(t, T)
plt.plot(losses)
plt.yscale('log')
Epoch 0/20000, loss: 11220.99
Epoch 2000/20000, loss: 3922.64
Epoch 4000/20000, loss: 2426.29
Epoch 6000/20000, loss: 1615.85
Epoch 8000/20000, loss: 1198.53
Epoch 10000/20000, loss: 1020.56
Epoch 12000/20000, loss: 923.80
Epoch 14000/20000, loss: 848.24
Epoch 16000/20000, loss: 783.72
Epoch 18000/20000, loss: 719.29
predsreg = netreg.predict(times)
prediction_temp_regularized = netreg.predict(times)
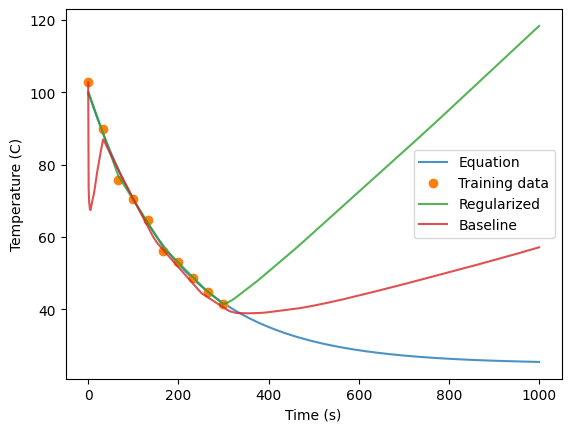
plt.plot(times, temps, alpha=0.8)
plt.plot(t, T, 'o')
plt.plot(times, prediction_temp_regularized, alpha=0.8)
plt.plot(times, prediction_temp_baseline, alpha=0.8)
plt.legend(labels=['Equation','Training data', 'Regularized', 'Baseline'])
plt.ylabel('Temperature (C)')
plt.xlabel('Time (s)')
Text(0.5, 0, 'Time (s)')
PINN#
def physics_loss(model: torch.nn.Module):
ts = torch.linspace(0, 1000, steps=1000,).view(-1,1).requires_grad_(True).to(DEVICE)
temps = model(ts)
dT = grad(temps, ts)[0]
pde = R*(Tenv - temps) - dT
return torch.mean(pde**2)
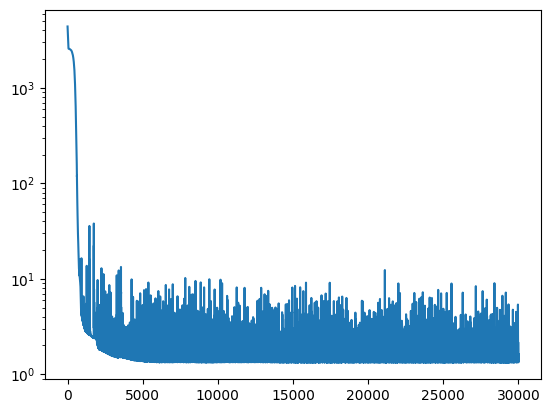
net_PINN = Net(1,1, loss2=physics_loss, epochs=10000, loss2_weight=1, lr=1e-4).to(DEVICE)
losses = net_PINN.fit(t, T)
plt.plot(losses)
plt.yscale('log')
Epoch 0/10000, loss: 4776.84
Epoch 1000/10000, loss: 2.23
Epoch 2000/10000, loss: 1.52
Epoch 3000/10000, loss: 2.01
Epoch 4000/10000, loss: 2.51
Epoch 5000/10000, loss: 1.69
Epoch 6000/10000, loss: 1.64
Epoch 7000/10000, loss: 1.84
Epoch 8000/10000, loss: 1.40
Epoch 9000/10000, loss: 1.37
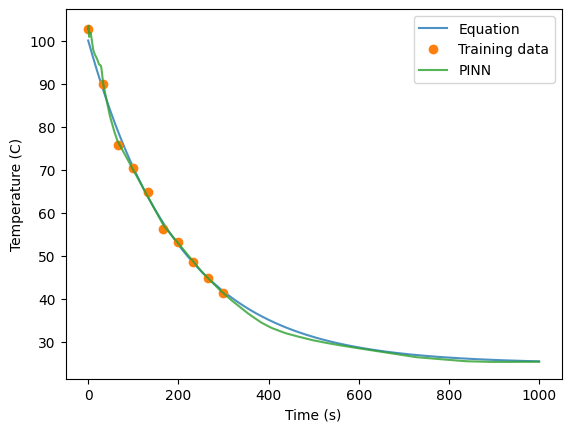
preds = net.predict(times)
plt.plot(times, temps, alpha=0.8)
plt.plot(t, T, 'o')
plt.plot(times, preds, alpha=0.8)
plt.legend(labels=['Equation','Training data', 'PINN'])
plt.ylabel('Temperature (C)')
plt.xlabel('Time (s)')
Text(0.5, 0, 'Time (s)')
Yes, Darcy flow is an excellent alternative example for introducing physics-informed neural networks (PINNs) in geosciences. Darcy’s law governs the flow of fluid through porous media, which is fundamental in hydrogeology, groundwater modeling, and petroleum reservoir engineering. Here’s how it can be framed for the class.
Darcy Flow Example#
Problem Statement: Consider a steady-state 1D flow in a porous medium governed by Darcy’s law and the continuity equation: [ q = -K \frac{dh}{dx}, \quad \frac{d}{dx}(q) = 0. ]
Here:
( q(x) ): volumetric flow rate per unit area,
( K ): hydraulic conductivity (a constant or spatially varying property),
( h(x) ): hydraulic head (height of the water table).
Substituting ( q = -K \frac{dh}{dx} ) into the continuity equation gives: [ \frac{d}{dx}\left(K \frac{dh}{dx}\right) = 0. ]
This is the governing PDE for the hydraulic head.
1D Simplified Problem#
For constant ( K ), the PDE reduces to: [ \frac{d^2h}{dx^2} = 0, \quad x \in [0, L], ] with boundary conditions: [ h(0) = h_0, \quad h(L) = h_L. ]
The analytical solution is: [ h(x) = h_0 + \frac{h_L - h_0}{L}x. ]
PINN Implementation for Darcy Flow#
Steps:#
Define the domain ( x \in [0, L] ).
Use a neural network to approximate ( h(x) ), the hydraulic head.
Encode the PDE ( \frac{d^2h}{dx^2} = 0 ) and boundary conditions ( h(0) = h_0 ), ( h(L) = h_L ) in the loss function.
Train the neural network to minimize the combined loss.
Python Code for PINN Implementation#
import torch
import torch.nn as nn
# Define the PINN model
class PINN_Darcy(nn.Module):
def __init__(self):
super(PINN_Darcy, self).__init__()
self.net = nn.Sequential(
nn.Linear(1, 64), nn.Tanh(),
nn.Linear(64, 64), nn.Tanh(),
nn.Linear(64, 1) # Output is h(x)
)
def forward(self, x):
return self.net(x)
# Define the PDE loss
def pde_loss(model, x):
x.requires_grad = True
h = model(x)
h_x = torch.autograd.grad(h, x, grad_outputs=torch.ones_like(h), create_graph=True)[0]
h_xx = torch.autograd.grad(h_x, x, grad_outputs=torch.ones_like(h_x), create_graph=True)[0]
return torch.mean(h_xx ** 2) # Loss for the PDE
# Define the boundary loss
def boundary_loss(model, x0, h0, xL, hL):
loss_0 = (model(x0) - h0) ** 2
loss_L = (model(xL) - hL) ** 2
return loss_0 + loss_L
# Training the PINN
def train_pinn(model, optimizer, x_interior, x0, h0, xL, hL, epochs):
for epoch in range(epochs):
optimizer.zero_grad()
loss_pde = pde_loss(model, x_interior)
loss_bc = boundary_loss(model, x0, h0, xL, hL)
loss = loss_pde + loss_bc
loss.backward()
optimizer.step()
if epoch % 100 == 0:
print(f"Epoch {epoch}, Loss: {loss.item()}")
# Setup example
L = 1.0
h0 = 10.0 # Hydraulic head at x=0
hL = 5.0 # Hydraulic head at x=L
x_interior = torch.rand(100, 1) * L # Random points in the domain
x0 = torch.tensor([[0.0]])
xL = torch.tensor([[L]])
h0 = torch.tensor([[h0]])
hL = torch.tensor([[hL]])
model = PINN_Darcy()
optimizer = torch.optim.Adam(model.parameters(), lr=1e-3)
train_pinn(model, optimizer, x_interior, x0, h0, xL, hL, epochs=1000)
# Visualize the result
import matplotlib.pyplot as plt
x_test = torch.linspace(0, L, 100).unsqueeze(1)
h_pred = model(x_test).detach().numpy()
plt.plot(x_test.numpy(), h_pred, label="PINN Solution")
plt.plot(x_test.numpy(), h0.numpy() + (hL.numpy() - h0.numpy()) * x_test.numpy() / L,
label="Analytical Solution", linestyle="--")
plt.xlabel("x")
plt.ylabel("Hydraulic Head (h)")
plt.legend()
plt.show()
Key Discussion Points#
Advantages of PINNs in Darcy Flow:
No need for discretization of the spatial domain (e.g., grids or meshes).
The model adapts to non-constant ( K(x) ) (e.g., heterogeneous conductivity).
Challenges:
Handling sharp contrasts in ( K(x) ) (e.g., multi-layered media).
Computational cost when solving 3D or transient problems.
Generalization in real-world scenarios with noise or missing data.
Extensions for Students#
Add Spatially Varying Conductivity: Modify the PDE to ( \frac{d}{dx}(K(x) \frac{dh}{dx}) = 0 ) and simulate heterogeneous ( K(x) ).
Include Transient Flow: Introduce time-dependence ( \frac{\partial h}{\partial t} = \frac{\partial}{\partial x}\left(K \frac{\partial h}{\partial x}\right) ).
Expand to 2D: Solve ( \nabla \cdot (K \nabla h) = 0 ) for a rectangular domain.
This example balances simplicity with geoscientific relevance, making it an ideal addition to the course.