3.4 GHCNd: Global Historical Climatology Network Daily#
Accurate Snow Water Equivalent (SWE) predictions rely heavily on reliable input data, including snow depth measurements. This section details the process of retrieving, processing, and refining snow depth data from the Global Historical Climatology Network Daily (GHCNd) dataset. The script discussed here automates the retrieval of snow depth data from ground stations, filters and cleans this data, and prepares it for use in SWE prediction models.
import pandas as pd
import requests
import re
from io import StringIO
import dask
import dask.dataframe as dd
all_ghcd_station_file = '../Data/all_ghcn_station_list.csv'
only_active_ghcd_station_in_west_conus_file = '../Data/active_station_only_list.csv'
snowdepth_csv_file = '../Data/active_station_only_list.csv_all_vars.csv'
mask_non_snow_days_ghcd_csv_file = '../Data/active_station_only_list.csv_all_vars_masked_non_snow.csv'
southwest_lon = -125.0
southwest_lat = 25.0
northeast_lon = -100.0
northeast_lat = 49.0
# the training period is three years from 2018 to 2021
train_start_date = "2018-01-03"
train_end_date = "2021-12-31"
3.4.1 Overview#
The GHCNd dataset provides daily climate records from numerous weather stations worldwide. This script specifically targets snow depth data (SNWD) from active ground stations within a defined geographical area. The process involves several key steps:
Downloading and Filtering Station Data: Identifying active stations within the specified region that report snow depth measurements.
Retrieving Snow Depth Observations: Downloading and processing snow depth data for the specified training period.
Masking Non-Snow Days: Refining the dataset to exclude non-snow days, focusing the data on relevant observations.
3.4.1.1 What data is being downloaded?#
Source: The data is sourced from the Global Historical Climatology Network Daily (GHCNd), a comprehensive dataset managed by the National Centers for Environmental Information (NCEI). It provides historical daily climate data from thousands of stations worldwide.
Features: The key feature targeted by this script is Snow Depth (SNWD), which is the depth of snow on the ground at the time of observation, typically measured in millimeters.
Station Metadata: Additional metadata about each station includes the station ID, geographical coordinates (latitude and longitude), and the operational period of the station (start and end years).
3.4.2 Downloading and Filtering Data#
The first step in this process is to download the list of all GHCNd stations and filter them based on geographical and operational criteria. This ensures that only active stations within the region of interest are considered.
3.4.2.1 Downloading and Converting Station Data#
The script begins by downloading the GHCNd station inventory file and converting it into a usable format. The relevant stations are then filtered based on their operational status (active in 2024) and location.
def download_convert_and_read():
url = "https://www.ncei.noaa.gov/pub/data/ghcn/daily/ghcnd-inventory.txt"
# Download the text file from the URL
response = requests.get(url)
if response.status_code != 200:
print("Error: Failed to download the file.")
return None
# Parse the text content into columns using regex
pattern = r"(\S+)\s+"
parsed_data = re.findall(pattern, response.text)
print("len(parsed_data) = ", len(parsed_data))
# Create a new list to store the rows
rows = []
for i in range(0, len(parsed_data), 6):
rows.append(parsed_data[i:i+6])
print("rows[0:20] = ", rows[0:20])
# Convert the rows into a CSV-like format
csv_data = "\n".join([",".join(row) for row in rows])
# Save the CSV-like string to a file
with open(all_ghcd_station_file, "w") as file:
file.write(csv_data)
# Read the CSV-like data into a pandas DataFrame
column_names = ['Station', 'Latitude', 'Longitude', 'Variable', 'Year_Start', 'Year_End']
df = pd.read_csv(all_ghcd_station_file, header=None, names=column_names)
print(df.head())
# Remove rows where the last column is not equal to "2024"
df = df[(df['Year_End'] == 2024) & (df['Variable']=='SNWD')]
print("Removed non-active stations: ", df.head())
# Filter rows within the latitude and longitude ranges
df = df[
(df['Latitude'] >= southwest_lat) & (df['Latitude'] <= northeast_lat) &
(df['Longitude'] >= southwest_lon) & (df['Longitude'] <= northeast_lon)
]
df.to_csv(only_active_ghcd_station_in_west_conus_file, index=False)
print(f"saved to {only_active_ghcd_station_in_west_conus_file}")
return df
download_convert_and_read()
len(parsed_data) = 4537908
rows[0:20] = [['ACW00011604', '17.1167', '-61.7833', 'TMAX', '1949', '1949'], ['ACW00011604', '17.1167', '-61.7833', 'TMIN', '1949', '1949'], ['ACW00011604', '17.1167', '-61.7833', 'PRCP', '1949', '1949'], ['ACW00011604', '17.1167', '-61.7833', 'SNOW', '1949', '1949'], ['ACW00011604', '17.1167', '-61.7833', 'SNWD', '1949', '1949'], ['ACW00011604', '17.1167', '-61.7833', 'PGTM', '1949', '1949'], ['ACW00011604', '17.1167', '-61.7833', 'WDFG', '1949', '1949'], ['ACW00011604', '17.1167', '-61.7833', 'WSFG', '1949', '1949'], ['ACW00011604', '17.1167', '-61.7833', 'WT03', '1949', '1949'], ['ACW00011604', '17.1167', '-61.7833', 'WT08', '1949', '1949'], ['ACW00011604', '17.1167', '-61.7833', 'WT16', '1949', '1949'], ['ACW00011647', '17.1333', '-61.7833', 'TMAX', '1961', '1961'], ['ACW00011647', '17.1333', '-61.7833', 'TMIN', '1961', '1961'], ['ACW00011647', '17.1333', '-61.7833', 'PRCP', '1957', '1970'], ['ACW00011647', '17.1333', '-61.7833', 'SNOW', '1957', '1970'], ['ACW00011647', '17.1333', '-61.7833', 'SNWD', '1957', '1970'], ['ACW00011647', '17.1333', '-61.7833', 'WT03', '1961', '1961'], ['ACW00011647', '17.1333', '-61.7833', 'WT16', '1961', '1966'], ['AE000041196', '25.3330', '55.5170', 'TMAX', '1944', '2024'], ['AE000041196', '25.3330', '55.5170', 'TMIN', '1944', '2024']]
Station Latitude Longitude Variable Year_Start Year_End
0 ACW00011604 17.1167 -61.7833 TMAX 1949 1949
1 ACW00011604 17.1167 -61.7833 TMIN 1949 1949
2 ACW00011604 17.1167 -61.7833 PRCP 1949 1949
3 ACW00011604 17.1167 -61.7833 SNOW 1949 1949
4 ACW00011604 17.1167 -61.7833 SNWD 1949 1949
Removed non-active stations: Station Latitude Longitude Variable Year_Start Year_End
424 AJ000037575 41.5500 46.6670 SNWD 1973 2024
446 AJ000037675 41.3670 48.5170 SNWD 1973 2024
454 AJ000037735 40.7167 46.4167 SNWD 1973 2024
475 AJ000037749 40.6500 47.7500 SNWD 1973 2024
485 AJ000037756 40.5330 48.9330 SNWD 1973 2024
saved to ../Data/active_station_only_list.csv
| Station | Latitude | Longitude | Variable | Year_Start | Year_End | |
|---|---|---|---|---|---|---|
| 70926 | CA001011500 | 48.9333 | -123.7500 | SNWD | 1991 | 2024 |
| 71000 | CA001012055 | 48.8333 | -124.0500 | SNWD | 1980 | 2024 |
| 71151 | CA001015105 | 48.3667 | -123.5667 | SNWD | 1980 | 2024 |
| 71190 | CA001015628 | 48.8167 | -123.7167 | SNWD | 1981 | 2024 |
| 71196 | CA001015630 | 48.8167 | -123.7167 | SNWD | 2007 | 2024 |
| ... | ... | ... | ... | ... | ... | ... |
| 750909 | USW00094143 | 43.5317 | -112.9422 | SNWD | 1954 | 2024 |
| 750992 | USW00094178 | 42.4786 | -114.4775 | SNWD | 1998 | 2024 |
| 751016 | USW00094182 | 44.8942 | -116.0997 | SNWD | 1998 | 2024 |
| 751035 | USW00094185 | 43.5947 | -118.9578 | SNWD | 1973 | 2024 |
| 751532 | USW00094290 | 47.6872 | -122.2553 | SNWD | 1986 | 2024 |
4529 rows × 6 columns
URL Download: The script begins by downloading the GHCNd station inventory file from the National Centers for Environmental Information (NCEI) website.
Data Parsing and Formatting: The raw text data is parsed using regular expressions and converted into a CSV format that can be easily processed by pandas.
Filtering: The script filters stations based on their operational status and geographical location, focusing on active stations within the defined latitude and longitude bounds.
Saving Processed Data: The filtered station data is saved to a CSV file, which will be used in the subsequent steps to retrieve snow depth observations.
3.4.2.2 Filtering and Saving Active Stations#
After filtering, the script saves the list of relevant stations, which will be used in subsequent steps to retrieve snow depth data. This step is crucial for ensuring that the data retrieval process focuses only on the most relevant stations, minimizing unnecessary data processing.
Key Points:
Geographical Filtering: Ensures that only stations within the defined latitudinal and longitudinal bounds are included.
Activity Status: Filters out stations that are no longer active, ensuring the data is current and relevant.
3.4.3 Retrieving Snow Depth Observations#
With the relevant stations identified, the next step is to retrieve snow depth observations from the GHCNd dataset for the specified training period. This involves downloading snow depth data from each station and processing it to ensure it is suitable for model training.
3.4.3.1 Processing Snow Depth Data#
The script uses Dask to parallelize the data retrieval process, efficiently downloading snow depth records from each station within the defined period. Dask is a powerful tool for handling large datasets, allowing for the concurrent execution of multiple data retrieval tasks.
import warnings
def get_snow_depth_observations_from_ghcn():
warnings.filterwarnings("ignore")
new_base_df = pd.read_csv(only_active_ghcd_station_in_west_conus_file)
print(new_base_df.shape)
start_date = train_start_date
end_date = train_end_date
# Create an empty Pandas DataFrame with the desired columns
result_df = pd.DataFrame(columns=[
'station_name',
'date',
'lat',
'lon',
'snow_depth',
])
train_start_date_obj = pd.to_datetime(train_start_date)
train_end_date_obj = pd.to_datetime(train_end_date)
# Function to process each station
@dask.delayed
def process_station(station):
station_name = station['Station']
# print(f"retrieving for {station_name}")
station_lat = station['Latitude']
station_long = station['Longitude']
try:
url = f"https://www.ncei.noaa.gov/data/global-historical-climatology-network-daily/access/{station_name}.csv"
response = requests.get(url)
df = pd.read_csv(StringIO(response.text))
#"STATION","DATE","LATITUDE","LONGITUDE","ELEVATION","NAME","PRCP","PRCP_ATTRIBUTES","SNOW","SNOW_ATTRIBUTES","SNWD","SNWD_ATTRIBUTES","TMAX","TMAX_ATTRIBUTES","TMIN","TMIN_ATTRIBUTES","PGTM","PGTM_ATTRIBUTES","WDFG","WDFG_ATTRIBUTES","WSFG","WSFG_ATTRIBUTES","WT03","WT03_ATTRIBUTES","WT08","WT08_ATTRIBUTES","WT16","WT16_ATTRIBUTES"
columns_to_keep = ['STATION', 'DATE', 'LATITUDE', 'LONGITUDE', 'SNWD']
df = df[columns_to_keep]
# Convert the date column to datetime objects
df['DATE'] = pd.to_datetime(df['DATE'])
# Filter rows based on the training period
df = df[(df['DATE'] >= train_start_date_obj) & (df['DATE'] <= train_end_date_obj)]
# print(df.head())
return df
except Exception as e:
print("An error occurred:", e)
# List of delayed computations for each station
delayed_results = [process_station(row) for _, row in new_base_df.iterrows()]
# Compute the delayed results
result_lists = dask.compute(*delayed_results)
# Concatenate the lists into a Pandas DataFrame
result_df = pd.concat(result_lists, ignore_index=True)
# Print the final Pandas DataFrame
print(result_df.head())
# Save the DataFrame to a CSV file
result_df.to_csv(snowdepth_csv_file, index=False)
print(f"All the data are saved to {snowdepth_csv_file}")
# result_df.to_csv(csv_file, index=False)
Active Stations
#
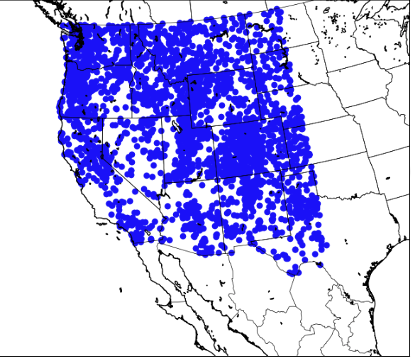
get_snow_depth_observations_from_ghcn()
(4529, 6)
An error occurred: "None of [Index(['STATION', 'DATE', 'LATITUDE', 'LONGITUDE', 'SNWD'], dtype='object')] are in the [columns]"
An error occurred: "None of [Index(['STATION', 'DATE', 'LATITUDE', 'LONGITUDE', 'SNWD'], dtype='object')] are in the [columns]"
An error occurred: "None of [Index(['STATION', 'DATE', 'LATITUDE', 'LONGITUDE', 'SNWD'], dtype='object')] are in the [columns]"
An error occurred: "None of [Index(['STATION', 'DATE', 'LATITUDE', 'LONGITUDE', 'SNWD'], dtype='object')] are in the [columns]"
An error occurred: "None of [Index(['STATION', 'DATE', 'LATITUDE', 'LONGITUDE', 'SNWD'], dtype='object')] are in the [columns]"
An error occurred: "None of [Index(['STATION', 'DATE', 'LATITUDE', 'LONGITUDE', 'SNWD'], dtype='object')] are in the [columns]"
An error occurred: "None of [Index(['STATION', 'DATE', 'LATITUDE', 'LONGITUDE', 'SNWD'], dtype='object')] are in the [columns]"
An error occurred: "None of [Index(['STATION', 'DATE', 'LATITUDE', 'LONGITUDE', 'SNWD'], dtype='object')] are in the [columns]"
An error occurred: "None of [Index(['STATION', 'DATE', 'LATITUDE', 'LONGITUDE', 'SNWD'], dtype='object')] are in the [columns]"
An error occurred: "None of [Index(['STATION', 'DATE', 'LATITUDE', 'LONGITUDE', 'SNWD'], dtype='object')] are in the [columns]"
An error occurred: "None of [Index(['STATION', 'DATE', 'LATITUDE', 'LONGITUDE', 'SNWD'], dtype='object')] are in the [columns]"
An error occurred: "None of [Index(['STATION', 'DATE', 'LATITUDE', 'LONGITUDE', 'SNWD'], dtype='object')] are in the [columns]"
An error occurred: "None of [Index(['STATION', 'DATE', 'LATITUDE', 'LONGITUDE', 'SNWD'], dtype='object')] are in the [columns]"
An error occurred: "None of [Index(['STATION', 'DATE', 'LATITUDE', 'LONGITUDE', 'SNWD'], dtype='object')] are in the [columns]"
An error occurred: "None of [Index(['STATION', 'DATE', 'LATITUDE', 'LONGITUDE', 'SNWD'], dtype='object')] are in the [columns]"
An error occurred: "None of [Index(['STATION', 'DATE', 'LATITUDE', 'LONGITUDE', 'SNWD'], dtype='object')] are in the [columns]"
An error occurred: "None of [Index(['STATION', 'DATE', 'LATITUDE', 'LONGITUDE', 'SNWD'], dtype='object')] are in the [columns]"
An error occurred: "None of [Index(['STATION', 'DATE', 'LATITUDE', 'LONGITUDE', 'SNWD'], dtype='object')] are in the [columns]"
An error occurred: "None of [Index(['STATION', 'DATE', 'LATITUDE', 'LONGITUDE', 'SNWD'], dtype='object')] are in the [columns]"
An error occurred: "None of [Index(['STATION', 'DATE', 'LATITUDE', 'LONGITUDE', 'SNWD'], dtype='object')] are in the [columns]"
An error occurred: "None of [Index(['STATION', 'DATE', 'LATITUDE', 'LONGITUDE', 'SNWD'], dtype='object')] are in the [columns]"
An error occurred: "None of [Index(['STATION', 'DATE', 'LATITUDE', 'LONGITUDE', 'SNWD'], dtype='object')] are in the [columns]"
An error occurred: "None of [Index(['STATION', 'DATE', 'LATITUDE', 'LONGITUDE', 'SNWD'], dtype='object')] are in the [columns]"
An error occurred: "None of [Index(['STATION', 'DATE', 'LATITUDE', 'LONGITUDE', 'SNWD'], dtype='object')] are in the [columns]"
An error occurred: "None of [Index(['STATION', 'DATE', 'LATITUDE', 'LONGITUDE', 'SNWD'], dtype='object')] are in the [columns]"
An error occurred: "None of [Index(['STATION', 'DATE', 'LATITUDE', 'LONGITUDE', 'SNWD'], dtype='object')] are in the [columns]"
An error occurred: "None of [Index(['STATION', 'DATE', 'LATITUDE', 'LONGITUDE', 'SNWD'], dtype='object')] are in the [columns]"
An error occurred: "None of [Index(['STATION', 'DATE', 'LATITUDE', 'LONGITUDE', 'SNWD'], dtype='object')] are in the [columns]"
An error occurred: "None of [Index(['STATION', 'DATE', 'LATITUDE', 'LONGITUDE', 'SNWD'], dtype='object')] are in the [columns]"
An error occurred: "None of [Index(['STATION', 'DATE', 'LATITUDE', 'LONGITUDE', 'SNWD'], dtype='object')] are in the [columns]"
An error occurred: "None of [Index(['STATION', 'DATE', 'LATITUDE', 'LONGITUDE', 'SNWD'], dtype='object')] are in the [columns]"
An error occurred: "None of [Index(['STATION', 'DATE', 'LATITUDE', 'LONGITUDE', 'SNWD'], dtype='object')] are in the [columns]"
STATION DATE LATITUDE LONGITUDE SNWD
0 CA001011500 2018-01-03 48.9333 -123.75 0.0
1 CA001011500 2018-01-04 48.9333 -123.75 0.0
2 CA001011500 2018-01-05 48.9333 -123.75 0.0
3 CA001011500 2018-01-06 48.9333 -123.75 0.0
4 CA001011500 2018-01-07 48.9333 -123.75 0.0
All the data are saved to ../Data/active_station_only_list.csv_all_vars.csv
Station Processing with Dask: Each station’s data is processed using Dask’s delayed function, allowing for parallel data retrieval. This significantly speeds up the process, especially when dealing with a large number of stations.
Data Features: The primary features extracted from each station’s dataset are:
STATION: The unique identifier for the weather station.
DATE: The date of the observation.
LATITUDE: The latitude of the station.
LONGITUDE: The longitude of the station.
SNWD: Snow depth in millimeters.
Data Filtering: For each station, the script retrieves snow depth data (SNWD) and filters it based on the specified training period. This ensures that only relevant data is included in the final dataset.
Data Concatenation and Saving: The retrieved data is concatenated into a single DataFrame and saved to a CSV file for further analysis.
3.4.3.2 Saving the Processed Data#
The final snow depth data, now filtered and cleaned, is saved to a CSV file. This file serves as the foundation for subsequent analyses and SWE prediction tasks. By automating the data retrieval and cleaning process, the script ensures that the dataset is ready for immediate use in model training.
3.4.4 Masking Non-Snow Days#
To refine the dataset further, the script masks out days with no snow depth observations. This step is important for focusing the analysis on days where snow depth measurements are meaningful, excluding days with zero or missing data.
def mask_out_all_non_zero_snowdepth_days():
df = pd.read_csv(snowdepth_csv_file)
# Create the new column 'swe_value' and assign values based on conditions
df['swe_value'] = 0 # Initialize all values to 0
# Assign NaN to 'swe_value' where 'snow_depth' is non-zero
df.loc[df['SNWD'] != 0, 'swe_value'] = -999
# Display the first few rows of the DataFrame
print(df.head())
df.to_csv(mask_non_snow_days_ghcd_csv_file, index=False)
mask_out_all_non_zero_snowdepth_days()
STATION DATE LATITUDE LONGITUDE SNWD swe_value
0 CA001011500 2018-01-03 48.9333 -123.75 0.0 0
1 CA001011500 2018-01-04 48.9333 -123.75 0.0 0
2 CA001011500 2018-01-05 48.9333 -123.75 0.0 0
3 CA001011500 2018-01-06 48.9333 -123.75 0.0 0
4 CA001011500 2018-01-07 48.9333 -123.75 0.0 0
Data Masking: The function creates a new column, swe_value, and assigns it a default value of 0. Where snow depth (SNWD) is non-zero, the swe_value is set to -999, effectively masking out these records.
Refinement for Analysis: This refinement step ensures that the dataset focuses on periods with significant snow depth, which are most relevant for SWE predictions. The masked data is then saved to a new CSV file, ready for use in further processing or analysis.